QB Express
Issue #26 ~ February 9th, 2008
"A magazine by the QB community, for the QB community!"
In This Issue
Staff
- Pete Berg (Editor)
- Imortis Inglorian
- MystikShadows
Contributors
- Lachie Dazdarian
- E.K. Virtanen
- Mentat
- Codemss
- Kiyote Wolf
- Moneo
- Michael (h4tt3n)
- Kristopher Windsor
- Sir_mud
- Regular Columns
- Articles & Editorials
- Tutorials
From The Editor's Desk
Written by Pete
Hello, hello, hello!
It's been over three months since the last issue of QB Express, but I think this issue more than makes up for it!
We've got NINE articles for you this month, covering everything from "The Art of Rounding" to FMOD, to Spring physics programming in Freebasic. We also have one of the biggest NEWS BRIEFS sections in QB Express history. You guys have been busy the past few months, and hopefully this issue will reflect that! You will definitely enjoy this issue.
On a side note, I apologize for falling off the regular release schedule again. Life is hectic for me these days, and sometimes I just can't find the free time to crank out a QB Express issue every month. (For instance, I went on a month-and-a-half trip between mid-December and the end of January, where I didn't have access to my PC, and couldn't really work on QB Express...so that certainly contributed to the delays.)
However, that's not to say that I've given up on the magazine! My goal is to release Issue #27 in March, Issue #28 in April, and so on, like in the first year of QB Express when the issues came out like clockwork. And the more you guys help me, the easier that will be. This brings me to the next section:
Submit To QB Express
You all know the drill. This magazine can't exist without people SUBMITTING articles, editorials, tutorials, reviews, news and feedback. This is not just a solo effort by me... it's a group effort by people throughout the QB community. If you have anything to submit, or have time to write something, DO IT!
If you want to write about something, but can't think of a topic, or need inspiration, check out the "Official QB Express Article Requests" thread! There have been quite a few articles requested -- and even if none of them strikes your fancy, we can help you come up with something that you would like to write about. If you're interested in getting your own monthly column or just want to write an article or two, by all means, do it! Anything that is submitted will be included!
I also want feedback and letters to the editor regarding this magazine. I want suggestions and critiques. What do you like? What don't you like? What could be done better? Let me know!
All submissions and feedback can be sent to qbexpress@gmail.com. You can also PM me on the Pete's QB Site or QBasic News message forums. If QB Express is going to continue to be so good, YOU need to contribute!
-Pete
Letters
Letter From E.K.Virtanen
Hi.
For a start, i want to say now i know what it is to build up an issue
like you have done this far. Took nearly 10 hours to build up last issue
of PCopy! And no double pay from a excess hours :D Never been this hard
and there is still lot's of "bugs" i need to fix.
"Accessibility and File Names" By notthecheatr was a good one
and i hope it wakes peoples attention about case sensitivity in
different platforms. Sure 85% of FB users has windows, but since FB
works with linux too, why not to give a few second of attention for
up/low case letters when creating a program? Internet is case sensitive
and we use it all the time so whats the big deal when creating a code?
I dont want to whine but just wanted to boost up this article a bit
here. Good work notthecheatr *thumbs up*
"User Oriented Programming" by St�phane Richard was also a
good one. I really love the way he writes. Even jerk non-nerd like me
can understand easily the points of a things which are not familiar
before reading. To mention here, i think Rick D. Clark has that same
ability to write tutorials in same way. Hopefully we see much more hes
tutorials in future.
"Angles in 2D environment..." by Lachie Dazdarian were
something i got help. I dont care much about these things normally but
this one helped me to resolve one hard bite i had with one ascii
program. To be honest, i didnt give much attention to first part of this
tutorial, but now i got so interested that i read them both for a few
times.
For final, i want to make a wish for all FB forum users. Could you
please mention a target platform if youre offering something like
"file.zip"? If there is compiled file, say for what platform it is and
if youre offering a source too, please mention if its only for windows?
I dont mean that this is a big deal, but it just irritates time to
time.
I am happy to see QBE is now back for good. It takes lot's of time
and energy and time to time there are nasty peoples complaining how it's
done so wrong. It is life, what you can do about it? I wish all the best
for all of you contributors and editors. Let the future of QBE be bright
and great.
Thanks, E.K.Virtanen
You're sure right that putting together a QB/FB magazine is a lot of work! I've already put in nearly a full day on this issue alone...and I don't mean a "9 to 5" day -- I mean 24 full hours. Finding a spare 24 hours to put together a magazine is tough, considering how little time all of us have...though I do believe the end result is worth it.
Good luck with PCopy! You have certainly surpassed QB Express, releasing two issues in less than the time it took me to put together one.
-Pete
Letter From MystikShadows
Hi everyone else but me ;-) (I know, a ridiculous attempt at hiding my insanity lol).
QB Express #25, count them, 25 issues so far. What a great number that is. Getting closer to 50 releases guys. One of the greater things about that is that with 25 releases behind it's back it's no wonder QB Express is where it is today. Needless to say I'm one of the happier ones here of that fact. 25 issues is quite an achievement for QB Express, a magazine that started off in a community and a language that was essentially dead or dying. Pete always said it, QB Express is a magazine created by the QB community, for the QB community. So although QB itself was on it's way out, QB Express was bound to survive because it was about the people, not the language. It could be called COBOL Express it would have survived too with these kinds of goals hehe. I think this is something some people *cough* pritchard *cough* would do well to remember, forget the name, the language the name is related to, QB Express is about the people.
I've been to the FreeBASIC forum and I've read what they had to say about Issue #25 being "sub par". I wrote my opinion there as well as a possible suggestion on at least part of a possible solution. So I'm not gonna repeat myself here. I do believe that QB Express represents a certain image to the community of course, but also to the outside world. I know that because I've sent people that asked me question to certain parts of QB Express issues. Everyone of them (9 or 10 of them so far) replied to me that:
They didn't know QB Express existed before I sent them there (Some didn't know FB existed either).
They didn't just read the article I pointed them to, they ended reading the whole issue and the other issues too.
They enjoyed the read hoped QB Express would go on with many more new releases.
Most Importantly, the really liked the fact that a community had it's own magazine, they thought highly of the people of this community because they could stand together and produce something like QB Express.
I think this says a lot about what QB Express is already and has the potential to become. If these 9 to 10 people start spreading the word around, you get where I'm going with this? And that's from people completely outside the community and even some from outside any BASIC dialects. This is what happens and when I tell people QB Express has been happening for about 3 years, their jaw practically falls off but in a good way, for us at least, they have drink juices and eat Jello for a while after. Now if QB Express has that kind of impact I think that at that point I understand why Lachie and maybe some others want QB Express to be �up to par� so to speak. Because of that impact on the outside world and the impact it has on the inside world of QB Express too. Why? Because QB Express represents it's people as well as it's contents I believe.
Now, notwithstanding the possible spelling and grammar errors, I think that the contents of QB Express #25 were very interesting. The news briefs are always one of the first things I check to make sure I didn't skip over anything. And well I did skip something because I didn't know about notthecheatr's font library that he released. I'm glad I know about it now though. Hehe. I think it's one of the first things that a lot of readers like to take a look at too. I know it impress at least a couple of the 9 or 10 that I sent to QB Express.
One thing I noticed about the last few issues is that things are taking a turn in the community. Articles like Deleter's �Multi-faceted nature of games, the dream, the design and the reality� are a perfect example of that and so is my User Oriented Programming article. It seems that the people are attacking not only programming challenges and techniques as is typically expected from an E-Zine, but people are also concerned about helping the success of programming projects both on the side of helping people by giving them tricks to stay motivated and finishing the projects but also on the side of helping people make games and programs that the users/players will love to play with by paying attention to how the features are presented and accessible to the users. Not sure how many people read Deleter's article but if they've given up on one or more projects for whichever reason, perhaps a reread of his article is in order. Great work there Deleter.
I also think there should be more articles like notthecheater's �Accessibility and File Names' which maybe he should have written in all lowercase characters ;-). FB is multi platform. Case sensitivity of file names is but one thing to consider when creating programs that is destined to be executed on more than one platform. I think a collection of discrepencies such as case sensitivity and path/file access rights and other things should be listed and considered in a complete �how to really be multi platform in your programming type of thing should be created, that's not just for FreeBASIC, but for any language that runs on more than one platform ;-). It would be a very useful thing to have indeed. Right down to adding some #IFDEF that do different tasks or load different libraries if needed in a given project. Really, anything that can and might be different on each OS should be in such an article.
And how about that comic section this issue huh? I've never seem so many of them in one issue ;-). There's a lot of creativity in there and I for one love the fact that they are in a magazine like QB Express, that too shows the people outside of our world so to speak, what we're all about hehe. About the pirate ship, he forgot the most important thing on it, the FLAG no pirate ship I know of doesn't have a flag. And I had a hunch about COBOL that got confirmed in this comic about how COBOL came to be hehe.
Dean Menezes �Fun with Recursion� I think is one of things to talk about. Not just recursion itself which is very useful in many cases, but just taking algorithms and explaining them. I think, if it's done right like it seems to be in Dean's case, that doing that, explaining them with a coding example is one of the greater ways there is to teach the subject to newcomers or people that do code but just never sat down and studied these algorithms. A lot of people just sit down and code, the hack at it until the darn thing works whereas if they would have known about one little algorithm that already exists they might have saved themselves hours if not days of coding so I would like to suggest that any algorithms that people can think of should be covered and submitted, just so they are there and known about. Great work Dean, great idea.
When I read RubyNL's first contributions, I had a hunch that writing came rather naturally. So did explaining, detailing everything in such a way that they are just understood. And this issue's �peek and poke tutorial� and �sphere mapping tutorial� just confirmed what I thought in the past issue. As I said before it's written in a way that one just reads and learns. RubyNL should be a teacher in my book because of the way everything is explored and detailed. Examples are concrete and pretty easy to follow (for me anyways) it's just a brilliant piece of creative art to read. Great work there. Looking forward to anything other contributions. So RubyNL? Keep on writing, you got at least one fan and I'm sure there's many more that think like I do.
I always wondered �how do you go about making someone understand what a particle engine is, what it's good for, how it works and so on�. The way notthecheater did it is a way I didn't quite expect, I was thinking in the line of particle engine theories and so on first, bringing in examples after the basis are covered. Well, after reading notthecheater's tutorial on particle engines, I stand (err sit, technically lol) currected I think his way of presenting particle engines in his tutorial is very unique, direct, and effective. The examples start off simple and stay simple even as he modifies them in the latter part of his tutorial. Two thumbs up to him. I'm looking forward to reading part two. Great work.
I wanna take time to congratulate Immortis on an excellent initiative. His QB Express formatting tool is an awesome idea that seems to be developed just as awesomely. Reading his article all about his tool also makes it seems very ease to use and a great help for those of us that love to format their articles (I won't mention any names hehe). I gave it a good try I happened to have two or three of the supported editors and they all seemed to work great and as expected with his tool. Fully automated no, like he said himself, but yeah, thinking about the QB Express �code� series of tags makes me appreciate his tool even more hehe. It's on my list of cool tools that's all I can say.
Let's see now, we have sphere mapping, and then we have floor mapping (by Codemss). What a great lineup for anyone interested in 3D programming don't you guys think? I like how Codemss kept his tutorial as concise and to the point as he did in this 2nd installment of his floor mapping series. The knowledge is there, the technique is there, and even the programming example is there, what else is there to expect? Put all that code in an editor, compile it and voila, a working floor mapping program that works and from which we can expand on and learn from. It doesn't get any better than this.
Lachie's second part to his �Angle in 2D and artificial smarts based on them� answered a few question that were raised when I read his first installment that's my idea of a good complete �series� on any given subject. The progression, the follow through of the basic ideas and concepts from the first installment into this second work makes it a great educative and informative read. Lachie, I don't know what you're gonna write about next, but I can't wait to read it. Keep up the great contributions and your commitment to keeping the community alive and �up to par� ;-) hehe. I know where you're coming from. And I've explained it at the beginning of this letter hehe.
Mentat is one of the writers that weren't sure about their contributions in the past 2 issues. They tested the field and well I don't think he needs to wonder no more, he's a good writer with a gift for presenting the information in an interesting and intelligent way. I've been learning a lot from his writings he seems to be able to bring out the one magic sentence, that weren't mentioned in past articles by different authors on the same subject, that just seem to click with my brain. I'm sure I'm not the only one to think that too. Great write once again with your Acceleration, Velocity and Position tutorial. Awesome stuff, keep it up.
Sure I maybe be the QB Express motivator, but I don't think it's just all about motivation per se in what I write. I think what I really try to emphasize is that every effort, no matter what level of effort it is, towards giving the community something that makes a community a community should be valued and respected. Look at the image it seems to be giving us to the outside world, that should say a lot right there. QB Express is one of those community strong points, so are competitions of course. And for the sake of repeating myself here as I have twice so far on the FreeBASIC forums I still think a community.freebasic.net should exist because the community is just as important as the product the community revolves around. In this case, it's FreeBASIC (and some QuickBasic too, hence the name in the first place). But without the people of the community, none of these would be what they are today.
Nevermind the spelling and grammar checks, QB Express #25 was an awesome piece of work that still manages to live up to it's name and no established reputation in the community (and from what I'm seeing, outside the community too) so keep on keeping on, all of you. Another great release, that's the bottom line whether it's spell checked or not hehe.
MystikShadows
Stephane Richard
As always, I appreciate the motivation. :)
As for QB Express #25 being "sub-par," I agree with everyone that had that assessment. In fact, I was the one who originally used that term to describe the issue, before everyone else started using it as well.
The problems with #25 were not so much in the content we did have -- but with the content we didn't have. I did a lousy job of collecting news briefs, and missed many important stories. We had new game reviews, there were no "Monthly Awards", no Competition, no new poll, etc. It's tough, because all of these sections take time and effort on my part, and I was in a rush to get the issue out before I went away on a trip. I made a conscious decision to release an unfinished issue, in the interest of getting it "to press," so to speak.
With this issue, I've taken the opposite philosophy, and done a very thorough job collecting news briefs, and have made sure that all of the important sections are represented -- even if it has meant that it got delayed quite a bit. I hope people will notice the difference. (Although there is no poll this time around, because I did not put one up before hand.) Despite a weak showing in the "Articles" department, with no game reviews and only two articles, I think this is a much stronger issue.
Hopefully when people see this issue, they will be motivated to submit even better content so that #27 is even better!
-Pete
Have a letter for the editor? Send all your rants, raves, ideas, comments and questions to qbexpress@gmail.com.
News Briefs
News from all around the QB community, about the latest games, site updates, program releases and more!
QB Site News
- New Games and a New Forum at the Freebasic Games Directory
-
Lachie Dazdarian has been doing a great job keeping the Freebasic Games Directory up-to-date these past few months.
In December, the FBGD launched a new forum, that has attracted a decent number of users, and in the last two updates, Lachie has added ELEVEN new Freebasic games. He has also been keeping a "watchlist" of promising Freebasic games that will make it into the directory once they are finished.
Here's the list of new games (and their ratings):
- Sokoban DBOS - 16/20
- Puzzle - 09/20
- Van Hascii! - 08/20
- Hedge Row - The Maze Game - 11/20
- Drone Rescue - 11/20
- Invader FB � The Final Story - 13/20
- Vandris Escape - 11/20
- Sector Shock - 12/20
- ORB! - 12/20
- Invatris - 10/20
- TubeRacer ver.0.58 - 16/20
|

|
News Brief by Pete
- What's the deal with QB45.com?
-
This Fall, the QB45.com domain name expired, and with it went Jofer's "Yeti" version of the site, which lived at the domain since 2004. Luckily, Marcade (best known for running NeoBasic), snatched up the domain to prevent it from falling out of the hands of the QB community.
Now, rather than the extensive QBasic files archive and news resource we have come to expect from QB45, there is just a simple message board.

The older QB45.com "Yeti" design; and the current message board.
When he took over, Marcade opted not to transfer the "Yeti" version of the site to his server, or to resurrect the older "Future Software" version of the site. Instead, Marcade claims he plans to create an entirely *new* site, featuring the famous files archive and content from QB45.com.
Marcade made this announcement in October, and since then, nothing has happened with the site.
Many consider the QB45 files archive to be an important public resource, and it is now unavailable. Marcade has even removed backups of the archive from the server entirely, so as to prevent other webmasters from using them to create a new website. (Despite this effort, though, Mike Doise claims that he plans to make a new site at QB71.com that features the archive. Mike Doise, if you remember, took over QB45.com once in the past and replaced the popular "Future Software" version with a widely-hated PostNuke based site.)
In November, I asked Marcade why he wouldn't just restore the Yeti version of the site, knowing that he is unlikely to make a new QB45 site. Here is his response:
I have the best intentions for QB45.com. This means I want to put a site here that will last, like NeoBASIC has, for years. This means it should require no/little maintenance.
But I also want to make sure it is simple and fast.
Jofers did an excellent job on his Yeti site (geez, calling Jofers site King Kong version site !!. It is a bloody Yeti!! Yeti is way cooler than King Kong !!) .. but it is his site, his scripts, his idea's.
In my opinion it was .. too big .. for qb45.com with only a few visitors.
Whatever ends up here will be less complex, smaller. If you would want to get an idea what I mean, look at NeoBASIC and Plasma's Phatcode. These will be the inspiration.
About the QB45 file archive. I assure you, I did not delete it!! I just move it. :-P Because I think it is a bad idea that bad QB45 clones, including the file archive, pop up every where. I cannot stop other people from sharing the archive. I am all for keeping QB alive .. but I will be sad if I see a dozen sites pop up with identical file system/file archives. It is not a good reminder to QB45.com
The reason I *snatched* QB45.com was not only to prevent it being run over by ads, but also to prevent some keyboard coybow putting up some half baked site.
QB45.com has served it's time and I am here to give it a well deserved and proper retirement.
There will be a decent site here.
The Archive will come back.
And it will be here to stay. No fucked up servers. No adds.
I have finished moving QB45.com, Neobasic ( and marcade.net) to a new server which is fast and reliable. I will have vacation in 2 weeks for about 6 weeks long. I plan to work on all three sites in this time.
Hope I answered your questions.
-Marcade
We shall see what happens. But judging by the nearly four-month period of inactivity, it's looking less and less likely that we will see anything happen with QB45.com anytime soon.
It's a shame to see such a valuable resource go to waste.
News Brief by Pete
- PCopy! Releases Issues #50 and #60
-
E.K. Virtanen, MystikShadows and company have been keeping up with the *other* BASIC programming magazine out there, PCopy! (If you're keeping tabs, that's two full issues since the last issue of QB Express came out.)
Here's the rundown on the issues:
PCopy! Issue #50 Nov 16'th 2007: Read - .zip archive.
Regular Columns:
* From Our Editing Desk (E.K.Virtanen)
* Submitting to PCOPY! (Stephane Richard & E.K.Virtanen)
* Letters To The Editors (Mixed Contributors)
* Letters To The Hartnell (Mixed Contributors)
* In The News (Mixed Contributors)
* Exit Issue (E.K.Virtanen)
Articles:
* About PCopy! (E.K.Virtanen)
*The mindset problem (Bill Williams)
* Interview with Eros Olmi (E.K.Virtanen)
Reviews & Presentations:
* VIXEN: An XBLITE GUI Generator (Guy (gl) Lonn�)
* Introducing Fatal Method Games (FMG)
* More about smallBasic (Chris Warren-Smith)
* 3D graphics in thinBASIC: (Petr Schreiber)
Tutorials & HowTo's:
* Coding Functions: (Guy (gl) Lonn�)
and
PCopy! #60 - Jan. 9th 2008: Read - .zip Archive
Regular Columns:
* From Our Editing Desk (Da Editors)
* Submitting to PCOPY! (MystikShadows & E.K.Virtanen)
* Letters To The Editors (Mixed Contributors)
* In The News (Mixed Contributors)
* Exit Issue (MystikShadows)
Articles:
* Reliving BASIC's History In One Website (MystikShadows)
* The Open Source Entity Demystified (MystikShadows)
* Interview with Pete Berg (E.K.Virtanen)
* Open Source Software For A Living (MystikShadows)
Reviews & Presentations:
* Introduction to sdlBasic (Cybermonkey)
* QBinux (Sebastian McClouth)
Tutorials & HowTo's:
* The ABC of the Xblite Programmer (Guy "gl" Lonne)
* An Xblite Primer (Guy "gl" Lonne)
News Brief by Pete
- Defining a Community. Why is Ours Lost?
-
Pritchard wrote a very interesting article recently, called "Defining a Community. Why is Ours Lost?", which compares the former QBasic community with the current Freebasic scene. Here is the beginning of his article, which I encourage you to read all the way through:
QBasic arguably had one of the greatest programming communities in existence. Everyone got together to do everything. People coded things and posted them and were generally congratulated, or given friendly tips, generally ignoring how terrible any single piece of code was. The single action of getting text input and affecting a single stat based on what number was given was an amazing feat - Maybe not amazing in the intuitive sense, but amazing in that it was entertaining.
QBasic was naturally fun. Why is this though? It wasn't just the language. It was the community. Can they be related?
Let's define what a community is. FreeBASIC does not have as friendly as a community as QBasic. It may have a larger one, but it simply does not feel like home to the larger majority of members.
(Continue reading...)
-Pritchard
This article spurred an active discussion about the state of the Freebasic community. Pritchard's opinion that the FB scene is not nearly as "fun" or "exciting" as the old QBasic community is a popular one -- and it's one of the main reasons that QB coders give for not switching to Freebasic. Needless to say, this article is worth a read.
Pritchard's many other articles
Pritchard has made a habit of posting interesting articles on the FreeBasic.net forum. (He should start up a whole magazine of just his editorials!) Here are some of the best ones:
News Brief by Pete
- notthecheatr Opens New FB Site
-
notthecheatr recently opened a new Freebasic programming site, featuring many of his original tutorials, articles and FB programs. You can find the site here: http://notthecheatr.phatcode.net
Of special note are notthecheatr's FB n00b Tutorials, a great introduction to Freebasic programming that I would reccommend to... well... n00bs.
News Brief by Pete
Project News
- The Chronicles of Galia
-
Juan Pablo Peloso, aka "BISI Inc." has released a new QBasic RPG called "Chronicles of Galia: The First Mission," which is a a continuation of a series of QB games called simply "Adventure" 1 through 3.

Chronicles of Galia is a fairly straightforward old-school RPG, starring a royal knight named Jean-Pierre. It has simplistic battle and scrolling system, and simple 320x200 VGA graphics, but it looks to be a fun game. Here is some information from the creator:
Introduction
Jean-Pierre is back in a fully enhanced and extended version of his original Adventure! The original quest of yore has been greatly expanded upon, and it has now become Jean-Pierre's largest, most expansive adventure yet!
Just like the other BISI games, The First Mission was programmed using 100% QBasic language, featuring colorful VGA graphics. It's a new beginning in the series, indeed. So, here it is; the revamped beginning of Jean-Pierre's legend has finally arrived! Witness the true story behind our favorite knight's first mission!
Jump into the mythical land of Galia and have fun!
Story
This is the story of a man. A man who lived in the land of Galia, long, long ago. His name was Jean-Pierre LeBlanc, and he was a knight. A knight who lost his fighting spirit after his father's untimely demise. Yes, Jean-Pierre was a knight who had ceased to fight.
One night, he found himself lost in the silent remnants of a ruined dungeon. Confused and disoriented, he wandered about, looking for a way out. This, my friends, is how it all began...
You can download the game and find out more about it at the official website: Chronicles of Galia.
And you thought the QB RPG scene was dead!
News Brief by Pete
- FreeBasic ver0.18.3 Released
-
On the final day of 2007, a new version of FreeBasic was released. Here's the news blurb, courtesy of coderJeff:
Const Qualifiers, QB compatibility updates, graphics library fixes, ported header updates, and general improvements on all platforms.
Compiler development has made significant progress since the -lang dialect option was introduced with the 0.17 release earlier in 2007. Developers are continuing to take advantage of the capability to both improve the future of the language in the -lang fb dialect while at the same time providing even better QB compatibility in the -lang qb dialect.
This release, the last one for 2007, marks approximately the 3 year anniversary release since the first public release of FreeBASIC. Thanks to all the users that started with us and the new users that have joined since then for their suggestions, encouragement, and enthusiasm.
Download links are available here.
News Brief by Pete
- Z!re is Ambitious
-
Z!re is working on two GIGANTIC games in Freebasic right now, that are definitely worth your attention. However, I'm going to let the projects speak for themselves, since Z!re's style of announcing and promoting games confuses me, so I don't know what information is relevant and what is just incoherent rambling. :)
-
Gods and Idols
Apparently a demonstration game to show the power of Z!re's "Field View Engine 2" -- which is supposed to allow MMORPG / open universe games.

More information: here.
-
Death Racer: Journey Beyond The Stars
Chapter I: The Antaren Solar Flare of Doom
A racing game set in outer space. Z!re started this project because someone complained that nobody had yet made a driving / racing game in FB.

More information: here and here
News Brief by Pete
- Xerol's Game of Life
-
Xerol has released a demo of his version of "Conway's Game of Life," complete with a video demonstration, over at his website.

"Basically, Conway's Game of Life with the third dimension used to show successive states over time. You can download the program (and source) here."
News Brief by Pete
- The QB64 Project Releases Demo #5
-
Just as FreeBasic is getting to the point that it can hardly compile even simple QBasic code, a guy named Galleon has stepped up to save the day. Here is a news post, courtesy of Dav, that will get you up to speed:
The 'QB64 Project' by Galleon is an exciting compiler project. It is an attempt at making a Qbasic-compatabile compiler that produces executables capable of running on newer operating systems, like Vista.
DEMO #5 has been released and has many improvements from the last release.
Check out this thread for more information on DEMO #5:
http://www.network54.com/Forum/585676/DOWNLOAD_QB64_DEMO_NOW
There is a dedicated forum for the 'QB64 project' here:
http://www.network54.com/Forum/585676/
Keep tabs on this project; it's looking incredibly promising!
News Brief by Pete
- Moon Project Updates
-
AlexZ's impressive RTS / strategy game / economy simulation Moon Project recently havd version 0.5 released.


In case you haven't heard of it, here's a brief description of the premise:
Description
You have landed on Moon and your goal is to sort of Gaia transform it to make it habitable. You do so by building water pumps that will make plants grow who then produce an atmosphere. To build water pumps you will need to build Metal Mines, Habitats, Solar Panels and Research Centers. Habitats can only be built with enough food which is also produced by the plants, so you really need to take care what you build or you are out of ressources and you can't finish the game. Though, I've balanced it to make it very easy, so don't worry.
You can find the latest version in this thread!
News Brief by Pete
- Lachie's scrolling engine
Lachie Dazdarian is working on a new scrolling engine, which could be used as the basis for many types of games. This could come in very handy for beginning game programmers.

The latest version features include:
- a map editor (which allows you to edit multiple layers, place portals, etc.)
- script driven engine and map editor (customize screen size, tile size, tileset file, etc.)
- 4 layers (base, foreground, collision, overlay)
- two types of collision (tile-based (base layer), and pixel perfect (collision layer))
- an example with 3 locations to walk around
Planned features:
- improved map editor
- sliding off tiles layer
- time-based movement
News Brief by Pete
-
- Adigun Remixes Aflib2
-
Adigun A. Polack has been working on a new version of Aflib2 for Freebasic, that is now 97% complete.

Here's the news from Adigun himself:
An AWESOME welcome-back and greetings to all of you splendid FreeBASIC people out there once more here, and I am so tremendously happy up front to tell you right now that AFlib2 Remixed is now 97% completed so far, with just a few more routines to go, plus an all-new documentation that I am gonna do that covers all of the routines that this newly revamped game library has to offer!!! ^-^=b !
The most exciting new feature is Pixel-perfect (PP) sprite collision detection, that Adigun says he spent four months perfecting.
You can download the library here: AFlib2 Remixed (Developing Preview ver 0.97b)
News Brief by Pete
- "Bullet-Cloud: Reign of Firepower" by vcatkiller
-
A newcomer to the FB scene, vcatkiller, recently released a demo of a new side-scrolling spaceshooter game called Bullet Cloud.

It looks very promising. For a demo version, more screenshots and more information, visit the Bullet Cloud website.
News Brief by Pete
- FreeBASIC Extended Library Release 0.2.1
-
 sir_mud has been busy lately with a great library project called The FreeBasic Extended Library. "The FreeBASIC Extended Library, a somewhat C++ style library for FreeBASIC providing many commonly used containers, constants and functions. FBEXT, as it is called, is modular also consisting of a minimum "core" containing the containers, error checking, debug helpers and a memory leak detector."
sir_mud has been busy lately with a great library project called The FreeBasic Extended Library. "The FreeBASIC Extended Library, a somewhat C++ style library for FreeBASIC providing many commonly used containers, constants and functions. FBEXT, as it is called, is modular also consisting of a minimum "core" containing the containers, error checking, debug helpers and a memory leak detector."
Some of the current modules include:
- an xml parser
- OpenGL style vector and matrix classes
- one function to load pngs, jpgs or bmps without previously knowing their dimensions or allocating memory
- a fully featured Sprite class with unlimited number of frames per sprite and pixel perfect collision checking with other Sprites, among others.
- and more!
Find out more about FBEXT at the Information Portal, or download it at the Download Page
News Brief by Pete
- Two Lords Nearing Completion
-
Nodtveidt, aka Nekrophidius, aka Epona Soft has been working on his game Two Lords ever since before QB Express launched in 2004 (it was one of the first games previewed in the Gallery). Anyway, after all these years, he has announced that the game is "ALMOST FINISHED."
Epona Soft released some more screenshots at the Freebasic Games Directory forum and posted some news:


Two Lords will likely be completed by summer. This version is still built using FB 0.14 but transition to the latest FB beta is in progress. After this version is completed, a DS port will be made. Plans for the true 3D version are still in the works, but I'm unsure if it will ever come to fruition due to lack of time and the presence of way too much competition (it seems everyone's making an FPS).
News Brief by Pete
- Some More Sweet Code Snippets and Games
-
The last few months, some people have posted some very useful QB routines that you should absolutely check out:
News Brief by Pete
- A* Pathfinding Demo by coderJeff
-
coderJeff posted a great A* Pathfinding Demo on the Freebasic.net forums in November.

"You can use the mouse buttons to set the starting and ending tiles, plus toggle the solid tiles. This is an A* pathfinding demonstration written in FreeBASIC that generates a display similar to the excellent beginners tutorial by Patrick Lester found at http://www.policyalmanac.org/games/aStarTutorial.htm "
This is a fun and useful routine. Check out coderJeff's demo right here.
News Brief by Pete
- Chuckie Egg Returns
-
A&F Software has released a primitive but fun game called Chuckie Egg Returns, that is similar in style to Lode Runner. The aim of the game is to "collect all of the eggs on each level whilst avoiding the swans." Simple enough!

You can download the game at: http://ssjx.co.uk/windows/chuckie.php
News Brief by Pete
Competition News
- ciw1973's Space Invaders Competition
-
After the success of ciw1973's first wildly successful Freebasic coding competition, he ran a second one in November. The task? Create an original game using only the graphics and sounds from the original version of Space Invaders. And like ciw1973's previous competition, real cash prizes were awarded to the winners!


All in all, there were EIGHT entries into this competition, and some fabulous games were produced.
The final results are as follows:
1st - "Orb" by Kristopher Windsor - 100 GBP
2nd - "Final Invader" by ChangeV - 50 GBP
3rd - "Sector Shock" by Ryan - 25 GBP
Congratulations to the winners, and be sure to check out all of the entries, which were recently added to the Freebasic Games Directory.
News Brief by Pete
Gallery
Written by Pete
Every issue QB Express features a preview and exciting new screenshots from an upcoming QB game. If you would like your game featured, send in some screenshots!
Kristopher Windsor's Projects
The last few months, Kristopher Windsor has been churning out lots of amazing graphics demos, OpenGL demos and Freebasic games. He is as talented as he is prolific, and so this month, I am going to dedicate the entire gallery to shots from his projects.
Kristopher: I hope this is okay with you, because I didn't ask you before hand!
OpenGL 2D Library
Based on the code at http://basic4gl.wikispaces.com/2D+Drawing+in+OpenGL, I have made a small library for hardware accelerated 2D graphics!
It has commands similar to FBGFX's Line, Circle, Pset, Draw String, Put, and Screen, and can create textures directly from a bitmap or FBGFX buffer.
It has full support for alpha blending through rgba() in the primitive functions, and an alpha value argument in g2Put().

(Source)
Maze


(Source)
Ride the Train

(Source)
SpaceWars

(Source)
Car Show


(Source)
Car Highway


(Source)
UnAlien

Kristopher's creative new alien invasion game: UnAlien
Objective:
Save you empire from the evil aliens!
Controls:
Up - accelerate up
Right - go right faster
Space - fire
Minimum CPU:
1GHz
New technologies:
- Macros to consolidate some common code
- New collision detection function
- Use of (graphic -> width) and a bitmap loading function, so the size of the graphics is defined by the actual bitmap file, instead of constants in the program
- Shr 1 instead of / 2




And that's not all!
Kristopher Windsor has made dozens of other projects in the past few years, and is one of the best FB programmers around.
Check out many of his other projects at his website:
FreeBasic Programs Directory
Got to ask ourselves a question � Where are we now?
Written by Lachie Dazdarian
How many of us actually remember today the first years of FreeBASIC?
In was the time when the QBasic community was much in the state as it is now, and the atmosphere of "moving on" and "giving up" was a constant thing. Ok, today it's more about "We are alive to spite FB!", but nothing is really different about that part of the community. Then FreeBASIC appeared when we though nothing could bring the old spirit of the community back and the atmosphere of creativity was fully restored in less than a month. Yes, it took some of us to realize the greatness and importance of FreeBASIC for the future (cough-cough), but quite quickly all the important figures of the old community were coding in FreeBASIC. We had a constant influx of tutorials, popular 32-bit libs were wrapped for FB, and people produced programs that were way beyond "compiler feature exploring" toys.
Do you remember the days of The Quest For Opa Opa, The Griffon Legend, Lynn's Legacy, and sometime later Antiman but still quite long ago? Allow me to mention my Star Cage and Poxie too.
Yes, I'm recalling the games we used to make mainly because I'm interested in game design, but one wonders what the hell happened. Shouldn't have we moved on from there or at least stayed on the same place, and not went backwards (still talking about games)? And what happened to old QB legends that were here in the beginning of FB but with time disappeared or stopped coming? Where are na_th_an, relsoft, Piptol, Nekrophidius or SJ Zero. Yes, Nek comes to Pete's forum, but why not in the FreeBASIC.net anymore? Does anyone but me bother to ask why?
Well, I�ll tell you what I think. We simply disregarded the community and three groups of people remained. One building and contributing the compiler, another exploring and playing with the new features and possibilities but only that, and bunch of others silently mooching from this open source project not interested on giving anything back. Not that they have to, but I don't have to like them, do I?
Perhaps too many things are happening at once. Like not long ago we had HGE library wrapped for FB. More recently FreeBasic Extended Library and Adigun's AFlib 2 Remixed were released. You can easily get lost in there, spending more time exploring those libs than actually making something with them. I wonder will ANY The Griffon Legend level project be released in ANY of those libs in the next....I don't know, 4 months. I hope my fears will be proved wrong.
The other aspect of the �community problem� is of course that FreeBASIC is not mainly a game design tool. It's much more than QBasic could be and was, and therefore much more people are doing completely different things in it which was not the case with QBasic. Interests are divided and cohesion is lacking. This of course can't be changed, but one hopped some people will be motivate to create game design oriented forums/sites, or GUI forum/sites, heavily maintained, not just created. Places that will bring together people with the same interests in using FreeBASIC.
I personally did try with my FreeBASIC Games Directory, but the community feedback was/is rather lacking, so one can also ask himself if such things are even desired. Most seem to be quite content with the support forum only. Maybe on the end, this turned into a programming community, and that's for me like being in a foreign land.
It honestly sadness me that people don't really care that much anymore about the community. I guess they are happy with waiting and playing with the constant upgrades to FreeBASIC, getting wet with C++ structure and OOP (how did we come from BASIC to this, I ask), dream about the next big commercial project of their and do nothing for others, like comment a new FB game that usually appears once in a month. A friend of mine who agrees with my thoughts cleverly summed it by saying that the old community was about the people and not the language, and now it's about the language.
So to end this incoherent and drab article in my usual style, I�ll say what I think happened - THE COMMUINTY DIED! Yes. And it couldn�t be deader.
Will a never one appear, I can only speculate. I�m not very hopeful, and I�m fearful if a new appears I�ll feel like Alice in Wonderland in it. So yeah, the good old times have gone for me. A cold and uncertain future is ahead.
Goodbye my community, goodbye my friendly place. You have been the one.
Visit Lachie's website: Lachie.Phatcode.Net
Writing Tutorials
Written by Codemss
Finding a subject
Find a subject that interests you, and that you understand. You don�t have to know everything about the subject, but writing on subjects that don�t interest you is very hard and often doesn�t result in great tutorials(it is possible though).
Always first think of what you want to reach. A short-well explained tutorial about the basics? Or an 10-pages one, that covers all the subjects details? Will you only give theory, or will you give (a part of? The whole?) code for it? Well, enough to think on.
It is also important that you don�t write on subjects that have been tutorialized since the ancient times. Unless the available tutorials don�t satisfy you on some fronts, or if you want to add something to them. And of course, if you want to make a series about something, some subjects just can�t miss, and a link to someone�s other site looks a bit dull.
You don�t have to know everything about the subject when you start writing, expecially when it�s only about the basics. You can search up things about the subject while the tutorial is in progress too.
An introduction
I often use an introduction, because you can make clear to the reader what he can expect. Also make clear if you assume some additional knowledge(about vector math or interpolation for instance) or abilities that you need to understand the tutorial or use the technique you explain. Also, you can tell how you find the subject, where you saw it first and what your experiences are when you tried to code them, and whatever you want more. But don�t make it too long, because it will get boring then.
The tutorial itself
This is the biggest part of the tutorial. The important thing is here to keep the text understandable and neat. Also, try to make a clear page. Don�t write a page full of text, press enter sometimes! Always try to make things 100% clear. Read your own text. If you don�t understand your won text, other people surely won�t! If you�re having troubles in how to explain something, don�t hesitate to make a picture. Pictures are often much better then words, and it makes also your tutorial �look better�, the reader will be more attracted to read your tutorial.

Don�t use pictures from other people, prefer to make your own. If you steal pictures anyway, give credits and a link! But always try not to do this, keep it original!
When you explain something, prefer a short explanation instead of just giving the code. At least, always describe what you do in the code. Also, pseudo-code is nice. It is fine for short pieces of code to make both pseudocode and qb/fb code (or any other language, but not in QBE). BTW, pseudocode is this kind of code:
Loop (For every pixel):
Calculate colour
End loop
There are no syntax rules for pseudocode. You just write it in a way that it is most clear. Don�t forget any steps, just like real programming languages, you have to type everything. Of course you can point to multiple lines of programming code with one pseudocode line, but you have to do everything you would do in real programming code too(except program language specific things).
If you have enough spare time, you can offer your email address and offer to give explanation or edit the tutorial if things aren�t clear. But, be smart, and don�t give your mail you use for your job or privat things as well when you expect very much mails. You mailbox may be overflowed with questions or reactions, and that isn�t nice ;).
Reaching the end
Well, while I�m reaching the end of this tutorial also, I will give some advice on the end of your tutorials. At the end, I usually make a conclusion, where I explain how you should use the knowledge you just gained. When there are different manners and techniques, I give the pro�s and con�s for every manner.
I also post greets and credits if there are any. Ow, and sometimes I list some ideas that can be done with that technique. Things I haven�t done (yet) and that could be very nice. When you�re planning to write a next tutorial, you can give the reader some information where it is about. This are just some ideas, you could write everything you want, but this is what I do usually. When the tutorial is finished, you let someone else read it, to gain suggestions about grammar faults, bugs in your code and your writing style. Also, always ask if everything was completely clear and if he/she understood everything. When it�s done, you can do (or let do) the fonts etc, so it looks nice. The standard Word font is nice but too plain, so you may use other fonts (like I don�t do :P).
Greets to:
Optimus
Biskbart
Relsoft
Lachie D.
Mac
Greets,
Codemss
If you want to mail me about anything:
basicallybest@live.nl
Or visit my web page:
http://members.lycos.nl/rubynl
Download a copy of this article: Writing_Tutorials.doc
Monthly Awards
Written by Pete
Site of the Month
The Freebasic Games Directory
http://games.freebasic.net
Webmaster: Lachie Dazdarian

When Lachie Dazdarian followed up his QBasic Games Directory with a Freebasic version, we all knew it was going to be good. Lachie's dedication to the QB and FB is unrivaled, and his thoroughness and attention to detail ensures that any project he works on will be a quality product. Well, the FBGD definitely lives up to our expectations.
Simply put, the Freebasic Games Directory is the single greatest resource for FB game programmers available anywhere. Lachie Dazdarian has singlehandedly gathered up just about every completed Freebasic game that's ever been released, and organized them into an attractive and incredibly useful database -- complete with screenshots, reviews and a comments feature, that make the games more accessable.
However, it wasn't until this month that the FBGD truly became a community of its own -- when Lachie launched a forum, that has quickly become one of the top places to discuss Freebasic game programming, and share games.
For being such a phenomenal resource and for its quickly-growing forum, the Freebasic Games Directory is our Site of the Month!
Programmer of the Month
coderJeff
http://coderjeff.ca
coderJeff has been a contributor to the Freebasic community since the beginning, and you probably know him as one of the main programmers on the Freebasic Compiler. Since V1ctor scaled back his involvement with FB development several months ago, coderJeff has stepped up to fill his shoes; acting as the Site Admin for Freebasic.net, and also actively developing on the compiler. On the side, coderJeff has also released several projects of his own -- most recently his A* Pathfinding Test; and is working on an (Unofficial) Freebasic Manual.
But what has impressed me most about coderJeff in the past month has been his dedication to making Freebasic backwards compatible with QBasic; and his activism in helping QBasic programmers bridge the gap between QBasic and Freebasic. One of the biggest issues the QB community has with Freebasic are the inconsistencies between supported QB and FB code, and coderJeff has worked especially hard to help confused programmers transition their QuickBasic code to Freebasic.
For his dedication to the Freebasic compiler project, and his work to unite the FB and QB communities, coderJeff is the QB Express Programmer of the Month.
Comics
Comic by sir_mud
We've got a pretty bare comics section this month, but luckily Sir_mud is back with a new God Object comic!
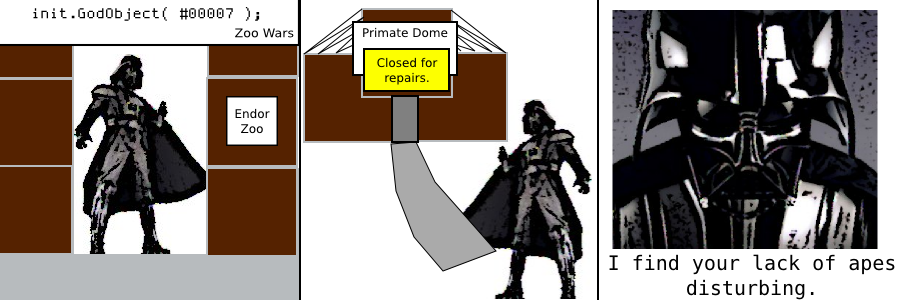
Click to view full size.
Have a QB/FB/programming related comic for QB Express? Mail it to qbexpress@gmail.com
Worms-style Scrolling Engine
Written by Codemss

Introduction
One of the great things of Worms was that the environment was almost completely destructible. You could make holes and tunnels through the whole landscape. This make some nice battle techniques possible. However, I will write more about how you can program this kind of landscapes. As an extra, I thought it would be nice to write something about scrolling and maps that are larger then the screen. I don�t know if this would work in Qbasic, it could be too slow. It is anyway a quite good way to save memory for big pixel maps and other things (I originally found this technique in a font tutorial by Jakob Krarup).
Theory about destructible landscapes
Destructible landscapes are in theory just a matter of clearing the map buffer where it is hit by an explosion. The hard thing about this is that you need very much memory to save the whole map in pixels, because you can use tiles. For simplicity, I will first do it with one single map that is screen-size in Qbasic:
DIM map(32001)
Then, we don�t use this as our screenbuffer or something, but we have just 2 kind of pixels in it:
2 = Indestructible
1 = Destructible ground
0 = Air
Now when we write to screen with a loop, we check if a pixel is not zero, so if there is ground (doesn�t matter if it�s destructible or not now). If it is, we texture it. You can apply three textures:
- An air texture for the sky (this could be an image as well as a texture as well)
- A texture for the destructible ground. Most people prefer some ground-colour for it. A brown, tiling texture is perfect.
- And of course one for the indestructible ground (often, metal or some metal colour is used).
Now we draw it like this:
DEF SEG = VARSEG(map(0))
p& = 4
FOR x = 0 TO 319
FOR y = 0 TO 199
SELECT CASE PEEK(map(p&))
CASE IS 0
REM Apply cloud picture or texture
CASE IS 1
REM Texture with destructible ground texture
CASE 2
REM Texture with indestructible ground texture
END SELECT
p& = p& + 1
NEXT
NEXT
Now we just use collision detection for our sprites. For the explosions we need to have a special map. We use it to say it if the ground is destructed, and if and how much damage is done to the character that it is hit by it (though this is not necessary as we can also just count how many pixels of the explosion are hitting the character). A map would look like this:

When the damage map hits a destructible pixel, it is removed. (I recommend round or random shapes instead of a map that leaves exact the same shape hole with every explosion). Ill call the white pixels damage pixels as they do damage. Instead of checking for every destructible pixel if it is hit by a damage pixel from the explosion map, you draw the explosion, and when on the place of a damage pixel is a destructible pixel, you erase it in the map. If you want to avoid DEF SEG (as it is not that fast), you should 1. Use a LUT to store 2. Use ASM. It is not easy but it is much faster and handles segments and such things better and faster then QB.
Here�s a little demo for you. I�m really sorry because it sucks so much, but you can still use it to look how the explosion sprite(really simple and ugly, sorry) and the explosion map are used. I�ve used here that the sprite is or drawed, or it doesn�t do any damage, so every drawed pixel is erased by the damage map, because it is drawed after it. If you don�t want this, you have to do this in the same order:
- Put explosion sprite
- (Eventually blit buffer to the screen)
- (Loop the explosion animation if you have one; goto step one then)
- Destroy the pixels with the damage map
- Re-paint the background
- (Eventually blit buffer to screen)
And here is my sucking demo. It doesn�t actually use a buffer, but just uses PSET and POINT, so it actually uses the buffer as a map. The way I would normally program it, is to make a buffer and PEEK and POKE to that. I could texture it too that way.
CLS
SCREEN 13
DEFINT A-Z
RANDOMIZE TIMER
FOR c = 16 TO 31
OUT &H3C8, c
OUT &H3C9, (c) / 31 * 63
OUT &H3C9, (c) / 31 * 63
OUT &H3C9, (c) / 31 * 63
NEXT
DIM ht(319)
FOR x = 0 TO 319
ht(x) = RND * 199
NEXT
CONST smooth = 20
FOR b = 1 TO smooth
FOR x = 0 TO 319
ht(x) = (ht((x - 1 + 320) MOD 320) + ht(x) + ht((x + 1) MOD 320)) \ 3
NEXT
NEXT
FOR x = 0 TO 319
LINE (x, 199)-(x, 199 - ht(x))
NEXT
DIM map(-25 TO 25, -25 TO 25), expl(-25 TO 25, -25 TO 25)
FOR x = -25 TO 25
x2 = x * x
FOR y = -25 TO 25
expl(x, y) = (31 - SQR(x2 + y * y) / 25 * 15)
IF expl(x, y) < 17 THEN expl(x, y) = 0 ELSE expl(x, y) = expl(x, y) + RND * 10 - 5
IF expl(x, y) < 17 THEN expl(x, y) = 0
IF expl(x, y) > 31 THEN expl(x, y) = 31
IF x2 + y * y < 625 THEN map(x, y) = 1
NEXT
NEXT
DO UNTIL INKEY$ <> ""
t! = TIMER + .2
ex = RND * 319
ey = RND * 199
FOR xx = -25 TO 25
FOR yy = -25 TO 25
IF expl(xx, yy) > 15 THEN
PSET (ex + xx, ey + yy), expl(xx, yy)
END IF
NEXT
NEXT
DO UNTIL TIMER >= t!: LOOP
t! = TIMER + .3
FOR xx = -25 TO 25
FOR yy = -25 TO 25
IF map(xx, yy) = 1 THEN
rx = xx + ex: ry = yy + ey
IF POINT(rx, ry) > 0 THEN PSET (rx, ry), 0
END IF
NEXT
NEXT
DO UNTIL TIMER >= t!: LOOP
LOOP
END
So. That is how you make a simple destructible terrain (I keep on typing destructable but Word helps me :D). But you only have a static, non-scrolling, boring map. Let�s make it bigger, so that we can scroll! First, though I will teach you how to actually use this map with holes.
Movement of the worms
To keep the worms on the right place their should be some kind of (primitive) collision detection. I suggest using an array that is the size of your worm (or other sprite ofcourse) where you hold which pixels are actually the worms and which pixels are empty. Then you only check the pixels which are not 0 (or another background colour). Kinda like the damage map and the explosion sprite. Here is the sprite, together with the collision detection array:

In this example you check only the pixels that are zero on the right map. You should only check the pixels that are new. New means that they are not already checked in previous collision detections.

Here, the red pixels are the �new� pixels. You should do collision test for the whole black area every time that a worm has gone to a completely new position (teleportation or the first time that the worms are being placed somewhere). What to do when one of the pixels is not empty? Well, you should decide if the pixel is (relatively!) low enough to let your worms climb upon it or if it�s to high for your worm.

If h is lower then *a certain height*
What you should do also, is checking the pixels below the worm.

Again, you should check only the red pixels. If they are empty, then move the worm down (it falls). Do this until:
- It has hit some (destructible) ground. You could subtract some lives either, so that the worms could die if they fall from a high platform.
- It is below the ground level. There are several things that you could do. You could let the worm disappear and act like it�s dead or either act just like the ground is destructible ground. So subtract some lives if the fall is high enough, and then just go on like normally.
Some kinds of projectiles
The most common weapons in worms are the grenade and the bazooka. They are relatively easy to code. You just have to do some simple collision detection for them. If the projectile hits a piece of ground, it should either explode(bazooka) or bounce(grenade). You can also make the explosion slightly bigger when the speed is bigger. The bouncing can be done by the easy way (invert speed on x or y-axis, dependant on where the collision was). You could also make some realistic kind of bouncing. Then you should have some way to calculate the normal on the point where the collision is and then use the reflection formula (originally used in raytracing, but also suitable for this purpose):
dot! = dot(Oldvector, Normalvector)
Newvector = Oldvector � 2 * dot! * Normalvector

All this vectors are 2d:
TYPE vector2d
X AS SINGLE
Y AS SINGLE
END TYPE
REM (Though you could use also integers with fixed point math)
Then, when we translate this from vector math to code:
TYPE vector2d
X AS SINGLE
Y AS SINGLE
END TYPE
REM (Though you could use also integers with fixed point math)
DIM Speed AS vector2d, Normal AS vector2d
dot! = dot(Speed.x, Speed.y, Normal.x, Normal.y)
Speed.x = Speed.x - 2 * dot! * Normal.x
Speed.y = Speed.y - 2 * dot! * Normal.y
For those who don�t know what the dot product is, here is the 2d version of it (there is also a 3d version of it, which is just the same but then with z component added too. Probably a 1d version also exists but I cant think of any possible purpose for this). Well, the code for the function is:
FUNCTION dot! (x1 AS SINGLE, y1 AS SINGLE, x2 AS SINGLE, y2 AS SINGLE)
dot! = x1 * x2 + y1 * y2
END FUNCTION
Big scrolling maps
Note: This is a manner of making big scrolling maps that I don�t know if it�s easy to make it run realtime, because I haven�t tried it. In theory this technique is quite easy, but when you actually use it is becomes much more complex due to the hard access to bits. To avoid this I suggest you use some lookuptables for the bit operations. I�ve explained how to make them in this chapter.
Bigger maps are cool to do. Remember that you have the textures stored not in the map, but separated? There is a reason for that. The map contains only if the pixel if destructible or empty. This is to save memory. We can, when use the binary mode, save big pictures in a smaller piece of memory. I suggest you�re using the way where you GET a piece if the screen loaded in an array. With this way you can save any portion of the screen with 256 colours. But when you have only two possible colours, the possibilities are much lower, so much less memory is used. When we use the same amount of memory(a screen size buffer), we can store 8 times larger pixel maps. Wow! But is has a downside. You can only store two kinds of pixels, so you have just:
- One texture for each kind of pixel. You could however make a tilemap, and paint the each pixel and lookup the texture at the tilemap, but this is somewhat hard.
- No un-destructible pixels. You can make these but then you can save �just� four times a screen-size map in an array with screen-size. You just have air and destructible pixels else.
But it�s the only way I know, else then just using extreme much memory. Now you know about this, I will actually explain how this is done. If you don�t understand the bits and byte part, read the font tutorial by Jakob Krarup, or a bit tutorial by Ximmer. But first try to understand this, because it is not so hard, and I think I explained it not so bad.
Let�s take one pixel. A pixel is represented by one byte. A byte is built up from 8 bits. Bits have value from either 0 or 1. The computer uses decimal numbers to built up all decimal numbers. This is some really important stuff for in the rest of the tutorial.
Let me explain how it is done:
In this picture, all bits are ON (=1). This 8-bit integer(byte) represents a value. We find it by adding all places where an one is in the above row(so if the bit is ON), multiplied by the �weight� of that bit(what�s standing below there). The weight for the nth bit is calculated by 2 ^ n. We start counting for n at zero, otherwise we would not get 1 at the begin.
So for the leftmost bit (I don�t call it �first� because the rightmost bit is actually the first), it�s value is 1 * 128. Now, let�s add everything together(I left out the 1 *, because they are kinds useless):
128 + 64 + 32 + 16 + 8 + 4 + 2 + 1 = 255
Hey! 255, that is the maximum colour in SCREEN 13! Right. The colours in screen mode 13 are also built up out of 8 bits. 8 Bits can have any value between 0 and 255. But when we want only two colours, we can do some stuff and use bits for our colour, so either zero or one.
Then we have to have a way to convert the value(0 - 255) to the bit thing and back.
Well, we can say:
- If the value AND (I mean the AND operation now ;)) the weight of the bit is more then zero, then the bit is one. If it�s zero, the bit is off.
There is some mathematical explanation for this but I won�t bore you with it. Read the bit tutorial of you want to know what AND exactly does.
The code to paint 8 pixels from one byte value(0-255) is as follows:
FOR x = 0 TO 7
IF value AND (2 ^ x) THEN PSET (x, 0), 15 ELSE PSET (x, 0), 0
NEXT
We can speed this code up with precalculating the values of n for every nth bit, but it�s smarter to remove the whole loop and do this:
IF value AND 1 THEN PSET (x, 0), 15 ELSE PSET (x, 0), 0
IF value AND 2 THEN PSET (x + 1, 0), 15 ELSE PSET (x + 1, 0), 0
IF value AND 4 THEN PSET (x + 2, 0), 15 ELSE PSET (x + 2, 0), 0
IF value AND 8 THEN PSET (x + 3, 0), 15 ELSE PSET (x + 3, 0), 0
IF value AND 16 THEN PSET (x + 4, 0), 15 ELSE PSET (x + 4, 0), 0
IF value AND 32 THEN PSET (x + 5, 0), 15 ELSE PSET (x + 5, 0), 0
IF value AND 64 THEN PSET (x + 6, 0), 15 ELSE PSET (x + 6, 0), 0
IF value AND 128 THEN PSET (x + 7, 0), 15 ELSE PSET (x + 7, 0), 0
In the game engine, you will need two LUT�s, one to convert from bits to a decimal value, that would look like:
DIM value(1, 1, 1, 1, 1, 1, 1, 1)
And another one that gives you the status of each nth bit with a certain value.
DIM bit(7, 255)
Where the second is the value of the byte you PEEK�d and the first is n (so you know the status of the nth bit). Of course this LUT�s are integer.
This is how we calculate out LUT�s:
DEFINT A-Z
DIM value(1, 1, 1, 1, 1, 1, 1, 1)
DIM bit(7, 255)
REM Calculate each bit of each value
FOR x = 0 to 255
b0 = SGN(x AND 1): b1 = SGN(x AND 2): b2 = SGN(x AND 4): b3 = SGN(x AND 8):
b4 = SGN(x AND 16): b5 = SGN(x AND 32): b6 = SGN(x AND 64): b7 = SGN(x AND 128)
value(b0, b1, b2, b3, b4, b5, b6, b7) = x
bit(0, x) = b0: bit(1, x) = b1: bit(2, x) = b2: bit(3, x) = b3
bit(4, x) = b4: bit(5, x) = b5: bit(6, x) = b6: bit(7, x) = b7
NEXT
The SGN() keeps the value between 0 and 1 (or -1 if there is a negative value, but we don�t have that here). It returns 0 for 0, -1 for any negative number and 1 for every positive number.
The second LUT is to do the drawing, you put the value of a byte in it, and the number of the bit that you want to know, and then it returns the value of that bit.
The first is to do the invert, so this is to edit the map (for example for explosions). You put the 8 bits in it, and it returns the value of the byte that it would be. Then you just POKE that in the memory at the right offset.
Now when you want a scrolling map, you should use PEEK and POKE to get any value between 0 and 255, so you can look that up and change it easily with the LUT�s. I believe that you can make a bit lookuptable in FB to make things easier, but I�m not sure of that.
Now one thing that may be a bit hard is to find the offset from where too start.

The offset where you have to begin is:
(Width * camy + camx) \ 8
Then you start at the ((Width * camy + camx) AND 7)th bit. This is because at each offset, 8 pixels are stored (or 4 if you use more kinds of terrains). Then you paint the terrain, starting at the calculated offset (I just explained you how to do that), then you paint 8 pixels from the byte at that offset, then you increase the pointer by one, so it is pointing at the next offset. You do that 40 times for a screen width of 320, then you set the pointer to the start offset plus the screen width, and draw it all over again. Then you do that until you reached the bottom of the screen.
Conclusion
When I look back at this tutorial I realize that there was a bit too much theory. This is mainly because I hadn�t enough time and motivation to cover every little thing in detail, and write the code for it. This is possible for small things like particular effects, but if you would do it for an engine (and especially ones like this, that are pretty complex) you would get something like 30 pages. I prefer a �light� tutorial, that is understandable and readable and one that still covers the very basic ideas behind it. Well, enough excuses about this tutorial which isn�t one of my best in my opinion. Please give me some feedback at basicallybest@live.nl.
Greets,
Codemss
Download a copy of this tutorial: Worms.doc
Functions and Local Variables
Written by Mentat
A function is a subroutine that gives back a value. Of course, they must be declared. Also, it is a good idea to pass numbers into a subroutine via arguments. They are also very useful for modularity and using local variables rather than global.
Keep in mind, this tutorial is about clarifying a subject and teaching it. This is not about the newest theory on how to construct neural paths for AI, or how to detect collisions in 5-dimensional space. This is text-book material, and neither particularly inspirational nor exciting.
The first thing to do is to do is initialize the function. Let�s have a function that divides a sum of numbers by a number. It requires three arguments, and returns one number.
If you want to copy, start below here:
'A SIMPLE FUNCTION PROGRAM------------------------
OPTION EXPLICIT
OPTION BYVAL
DECLARE FUNCTION GET_USER_INPUT OVERLOAD(AS SHORT) AS SHORT
DECLARE FUNCTION SUM_DIVIDE(A AS DOUBLE, B AS DOUBLE, C AS DOUBLE)AS DOUBLE
DECLARE FUNCTION GET_USER_INPUT() AS DOUBLE
DECLARE FUNCTION GO_AGAIN() AS DOUBLE
DECLARE SUB DISP_ANSWER(ANSWER AS DOUBLE)
DIM ANS AS DOUBLE
DIM LIST(3) AS DOUBLE
DIM TRY_AGAIN AS SHORT
DIM A_NUMBER AS SHORT
DO
FOR A_NUMBER = 1 TO 3
LET LIST(A_NUMBER) = GET_USER_INPUT()
NEXT A_NUMBER
LET ANS = SUM_DIVIDE(LIST(1), LIST(2), LIST(3))
CALL DISP_ANSWER(ANS)
LET TRY_AGAIN = GO_AGAIN()
LOOP WHILE TRY_AGAIN
STOP
'FUNCTIONS----------------------------------------------------------
FUNCTION SUM_DIVIDE(A AS DOUBLE,B AS DOUBLE,C AS DOUBLE)AS DOUBLE
PRINT ""
IF C<>0 THEN RETURN (A+B)/(C)
PRINT ""
PRINT "Error in the divisor!"
BEEP
RETURN 0
END FUNCTION
FUNCTION GET_USER_INPUT() AS DOUBLE
DIM A_NUMBER AS DOUBLE
INPUT "Please enter a number: ", A_NUMBER
RETURN A_NUMBER
END FUNCTION
FUNCTION GET_USER_INPUT(USELESS AS SHORT) AS SHORT
RETURN 42
END FUNCTION
FUNCTION GO_AGAIN() AS DOUBLE
DIM TRY_AGAIN AS STRING
PRINT ""
INPUT "Do you want to try again? ", TRY_AGAIN
LET TRY_AGAIN = UCASE(TRY_AGAIN)
IF TRY_AGAIN = "YES" OR TRY_AGAIN = "Y" THEN RETURN 1
IF TRY_AGAIN = "NO" OR TRY_AGAIN = "N" THEN RETURN 0
PRINT "Bad input!"
BEEP
RETURN GO_AGAIN()
END FUNCTION
'SUBROUTINES--------------------------------------------------------
SUB DISP_ANSWER(ANSWER AS DOUBLE)
PRINT "Your answer is ",ANSWER
END SUB
�END OF PROGRAM----------------------------------------------------
Stop copying. If you don�t, you just might get an error in you�re compiler if it permits pasting.
I doubt it will work in QB; most likely because I�m passing functions without parameters. For those of you with only QB, pretend that this program is running. It�s FB tested, and although it�s practically unpractical, not to mention rather inefficient, it serves as an educational tool.
To start off explaining the program, and elucidate you on functions, I�ll start from the top, and work all of my way down.
First thing is the top two commands. OPTION EXPLICIT and OPTION BYVAL.
OPTION EXPLICIT is an excellent debugging tool. It tells the compiler to flag an error if it sees an uninitialized variable. It�s to protect against typos. It actually helped me when I wrote the code. I originally put FOR A_NUMBER = 1 TO 3 ... NEXT A. Actually, it was supposed to be NEXT A_NUMBER. Yes, it�s extra work to initialize variables without using them, but it protects from typo bugs, and initializing variables is a good habit.
OPTION BYVAL tells the compiler to accept values, rather than references. I don�t know much about it, other than it solved an old bug I had.
The next command is my declaration of the function SUM_DIVIDE. Due to lack of space and word-wrap, the last double moved to the next line. So for those who already copied and attempted to run the program, you might get an error if you didn�t notice this. Just move it back. The other functions and subroutines also were declared with the format of DECLARE <FUNCTION|SUB> <NAME>(PARAMETER_ONE AS DOUBLE, PARAMETER_TWO AS SINGLE, PARAMETER_THREE AS STRING, ... , PARAMETER_N AS SHORT) AS LONG. In order, declare the function�s name, the parameters with each type, and top it off with the type of the return value. You may not even need parameters, but remember to include the empty parenthesis. Such as FUNCTION GO_AGAIN( ).
Next is dimensioning the main variables themselves. Notice that I did NOT use common shared. Which means that no function is messing with any variables that it shouldn�t mess with. Global variables are evil. Repeat, global variables are evil. Just like GOTO. Use them only when local variables can�t do something well. But then again, that�s what pointers are for.
Now for the main body. The DO loop. The first thing in the main loop is the FOR loop. It runs three times, to get user input three times. GET_USER_INPUT( ) does what its names says; it gets the user�s input. And the FOR loop stores it to an array.
The next thing that is done is loading the list into the function SUM_DIVIDE and then storing the answer to the variable ANS. Then the variable is displayed and the user is asked if he or she wants to try again.
For those of you who are new to programming and/or Boolean logic, you might have noticed what I did to end the WHILE loop. I put WHILE TRY_AGAIN. This is not a typo. I don�t have to put WHILE TRY_AGAIN = 1. The computer assumes that as long as TRY_AGAIN is not zero, it is true.
Onward, to the homeland of functions and subroutines. First on the line, the almighty Function FUNCTION SUM_DIVIDE itself. Here�s the purpose of the program. It doesn�t matter where you put it. Okay, there are limits. But why on earth would anybody declare it in a FOR loop? It will still take its arguments and spit out a brand new number, if it�s properly declared and there aren�t any bugs or typos.
I�ll let you figure out the other functions. You might have noticed that I put the same function GET_USER_INPUT twice, with different parameters. The second function with the extra parameter that just returns 42 (why not?) is called an overloaded function. It�s a neat trick, though useless in my program. The overloaded function (which must go before the original) has a different set of arguments. The reason for this is that sometimes you might want to put these numbers in a function (ex: all double), and other times you want to input strings. And you want it under the same name, but different ways to process the numbers due to different natures of the numbers. You don�t have to do this, but it looks cool and has practical applications.
Oh, and subroutines can also take parameters. It keeps the variables local, but �transports� them through arguments and returns (for functions, subs don�t return anything).
Here�s an instance for using functions and subs. Use a subroutine that takes six parameters � the x and y coordinates for a triangle � and print them. Use a function to move the vertices.
That�s all I have to say about functions. So if you see F(x) = x� + 4x + 5, you know that you can plug it to the computer.
If you have any comments or questions, open your compiler and press F1. If you have any further comments or questions, about this tutorial, please find a way to ask me.
Hopefully, I can answer any questions. Thank you for giving my tutorial some interest.
Download a copy of this tutorial: Funct.doc
GridMulti: Using string variables to eliminate wasted stack space
Written by Kiyote Wolf
Every programmer dreams of their program turning out the best it can be, after say,.. about 200 revisions.. you have something that looks like a finished piece.
I say 200 revisions, cause I like to save alot.
When your main module grows to the biggest it can be, you become limited by your program's own use of defined arrays and variables verses the length of the overall code.
One of the tricks I came up with when programming in a strict structured language like Turbo Pascal, was to define an array of 100 intergers, 100 strings, and use those as my variables. That way, instead of defining a name for every variable, if I commented my use of the arrays well, I could tweak the code rather trouble free.
Well, that is our achille's heel in QBasic. We are free to make as many variables as we want, even if we are unaware of how we make unnecessary duplicates of the same variables, only with a slightly different name.
That's where string variables encoded to shuttle groups of values can help keep your string usage to a minimum.
Using a simple scheme to encode values and string entries into one long chain, we can use a few routines to pull the data off or check against the data and create markers to grab data further down the chain.
******** WORKING FUNCTIONS, READY TO COPY & PASTE INTO CODE ******
FUNCTION GridCnt (in$)
Cnt = -1
IF in$ <> "" THEN
FOR Nul = 1 TO LEN(in$)
Char$ = MID$(in$, Nul, 1)
IF Char$ = ";" THEN
Cnt = Cnt + 1
END IF
NEXT Nul
END IF
IF Cnt = -1 THEN Cnt = 0
GridCnt = Cnt
'<> Count number of elements by counting the separators.
END FUNCTION
FUNCTION GridDelta$ (TmpStrg$, Ofs, NewStrg$)
Cnt = GridCnt(TmpStrg$)
IF Ofs > Cnt THEN Cnt = 0
TmpStrg2$ = ""
IF Cnt THEN
FOR Nul = 0 TO Cnt
IF Nul = Ofs THEN
IF Nul THEN
TmpStrg2$ = TmpStrg2$ + ";" + NewStrg$ 'vert2$(NewStrg$)
ELSE
TmpStrg2$ = NewStrg$ + ";"
END IF
ELSE
IF Nul THEN
TmpStrg2$ = TmpStrg2$ + ";" + GridMultiVar$(TmpStrg$, Nul)
ELSE
TmpStrg2$ = GridMultiVar$(TmpStrg$, Nul)
END IF
END IF
NEXT Nul
GridDelta$ = TmpStrg2$ + ";"
ELSE
GridDelta$ = TmpStrg$
END IF
'<> Replace one element with a new value in the chain
END FUNCTION
FUNCTION GridIF (DataCmd$, Expr$)
'<> Does the left piece of the expression match?
GridIF = 0
IF Expr$ <> "" THEN
ExprLen = LEN(Expr$)
END IF
Nul2 = GridCnt(DataCmd$)
IF Nul2 THEN
FOR Nul = 0 TO Nul2
IF LEFT$(GridMultiVar$(DataCmd$, Nul), ExprLen) = Expr$ THEN
IF Nul = 0 THEN
GridIF = -1
ELSE
GridIF = Nul
END IF
END IF
NEXT Nul
END IF
'<> Find the first instance of a keyword, located on the left of the entry
'Return the location, similar to INSTR$
END FUNCTION
FUNCTION GridIFExpr$ (DataCmd$, Expr$)
'<> Does the left piece of the expression match?
IF Expr$ <> "" THEN
ExprLen = LEN(Expr$)
END IF
Nul2 = GridCnt(DataCmd$)
IF Nul2 THEN
FOR Nul = 0 TO Nul2
IF LEFT$(GridMultiVar$(DataCmd$, Nul), ExprLen) = Expr$ THEN
IF LEN(DataCmd$) > LEN(Expr$) THEN
GridIFExpr$ = MID$(DataCmd$, ExprLen + 1)
ELSE
GridIFExpr$ = "BLANK"
END IF
END IF
NEXT Nul
END IF
'<> Check for a combined entry..
'InString$="TEST;PRINT;COLOR255;"
'z$=GridIFExpr$(InString$,"COLOR")
'z$ now = 255
END FUNCTION
FUNCTION GridMID$ (InStrg$, Start, Leng)
IF InStrg$ <> "" THEN
Cnt = GridCnt(InStrg$)
IF Cnt THEN
TmpStrg$ = ""
FOR Nul = Start TO Start + Leng - 1
TmpStrg$ = TmpStrg$ + GridMultiVar$(InStrg$, Nul) + ";"
NEXT Nul
END IF
END IF
IF TmpStrg$ = "" THEN
GridMID$ = "BLANK"
ELSE
GridMID$ = TmpStrg$
END IF
'<> Similar to MID$, allow us to pull out a usable chain from a longer
'one so we can start a new chain, or analyze it outside the longer chain.
END FUNCTION
FUNCTION GridMulti (in$, Cnt)
IF in$ = "" THEN EXIT FUNCTION
'ex.: All entries must have a ; after numerics--one two or 3
z = INSTR(in$, ";")
SELECT CASE Cnt
CASE 0
in2$ = in$
CASE ELSE
in2$ = in$
FOR z = 1 TO Cnt
w = INSTR(in2$, ";")
in2$ = MID$(in2$, w + 1)
NEXT z
END SELECT
GridMulti = VAL(in2$)
'Pull out a single numeric value from a chain.
END FUNCTION
FUNCTION GridMultiVar$ (in$, Cnt)
IF in$ = "" THEN EXIT FUNCTION
'ex.: All entries must have a ; after numerics--one two or 3
z = INSTR(in$, ";")
SELECT CASE Cnt
CASE 0
in2$ = in$
CASE ELSE
in2$ = in$
FOR z = 1 TO Cnt
w = INSTR(in2$, ";")
in2$ = MID$(in2$, w + 1)
NEXT z
END SELECT
IF in2$ <> "" THEN
A$ = in2$
NoFlag = 0
FOR z = 1 TO LEN(in2$)
B$ = MID$(in2$, z, 1)
SELECT CASE B$
CASE CHR$(0)
IF 1 = 0 THEN MID$(A$, z, 1) = CHR$(32)
CASE ";"
NoFlag = -1
MID$(A$, z, 1) = CHR$(32)
FOR w = z TO LEN(in2$)
MID$(A$, w, 1) = CHR$(32)
NEXT w
CASE ELSE
IF NoFlag THEN cutat = z
END SELECT
NEXT z
IF A$ <> "" THEN
IF LEN(A$) > 1 THEN
IF cutat - 1 < 1 THEN
REM
ELSE
A$ = LEFT$(A$, cutat - 1)
END IF
END IF
END IF
in2$ = A$
END IF
GridMultiVar$ = LTRIM$(RTRIM$(in2$))
'<> Pull out a single string value from a chain.
'The complex stuff near the end is correction for chr$(0), chr$(32).. etc..
END FUNCTION
FUNCTION vert$ (in)
vert$ = LTRIM$(STR$(in))
'Make a numeric into a string with no leading space
END FUNCTION
FUNCTION vert2 (strng$, offs)
vert1 = 0
IF strng$ <> "" THEN
vert1 = ASC(MID$(strng$, offs, 1))
END IF
vert2 = vert1
'Convert something encoded into ASCII back into Decimal using MID$.. blah ..
END FUNCTION
FUNCTION vert3 (HexIn$)
vert3 = VAL("&H" + LTRIM$(HexIn$))
'Take raw HEX and make them VAL() compliant for turning into values.
END FUNCTION
FUNCTION vert4$ (in)
vert4$ = LTRIM$(STR$(in)) + ";"
'Make a numeric that can be added directly to a chain.
END FUNCTION
FUNCTION vert5$ (inval)
vert5$ = RIGHT$("000" + LTRIM$(STR$(inval)), 3) + ";"
'Create a visually pleasing numeric string from a value.
'Used for showing counters and values on screen.
END FUNCTION
FRAGMENT OF A WORKING FUNCTION THAT USES THESE ROUTINES
FUNCTION MouseOver$ (in$)
'SHARED MouseX,MouseY ' global variables -- of course we assume this..
'Example of a heavily used routine of mine to check mouse position.
z = QBEX(3)
MouseOver$ = "BLANK"
SELECT CASE in$
CASE "RGBPAL"
ulx = 122
uly = 10
lrx = 249
lry = 104
IF (MouseX >= ulx) AND (MouseX <= lrx) AND (MouseY >= uly) AND (MouseY <= lry) THEN
xat = INT((MouseX - ulx) / 8)
yat = INT((MouseY - uly) / 6)
cat = (xat + yat * 16) AND 255
MouseOver$ = "RGBPAL;" + vert4$(cat)
ELSE
cat = 0
MouseOver$ = "BLANK;BLANK;"
END IF
CASE "CTRL4"
ulx = 6
uly = 26
lrx = 6 + 37 * 17
lry = 26 + 42 * 9
xat = (MouseX - ulx) \ 37
yat = (MouseY - uly) \ 50
IF (MouseX > ulx) AND (MouseY > uly) THEN
xat2 = MouseX - (ulx + xat * 37)
yat2 = MouseY - (uly + yat * 50)
MouseOvr$ = "CTRL4;" + RIGHT$("000" + vert$(xat), 3) + ";" + RIGHT$("000" + vert$(yat), 3) + ";"
MouseOver$ = MouseOvr$ + RIGHT$("000" + vert$(xat2), 3) + ";" + RIGHT$("000" + vert$(yat2), 3)
ELSE
MouseOver$ = "BLANK"
END IF
END SELECT
END FUNCTION
FRAGMENTS OF CODE THAT USES THESE ROUTINES
Example 1
REDIM Out$(7)
Out$(0) = ""
Out$(1) = ""
Out$(2) = ""
Out$(3) = ""
Out$(4) = ""
Out$(5) = ""
Out$(6) = ""
DotC = 15
DO 'start selection loop
IF MouseLeft THEN
z = QBEX(6)
Out$(0) = MouseOver("EXIT")
Out$(1) = MouseOver("CLRBAR")
Out$(2) = MouseOver("EXIT2")
Out$(3) = MouseOver("CLRCHART")
Out$(4) = MouseOver("SAVE")
Out$(5) = MouseOver("LOAD")
Out$(6) = MouseOver("CURSORCLR")
Out$(7) = MouseOver("DONEEDIT")
Example 2
IF LEFT$(Out$(6), 5) <> "BLANK" THEN
FontMd = 8
PushRGB red%, green%, blue%, 11
red% = 0: green% = 0: blue% = 0
Cube24 515, 100, 515 + 8, 100 + 20
msg2$ = "CHAR;" + vert$(FontCr) + ";" + vert4$(redTmp1%) + vert4$(grnTmp1%) + vert4$(bluTmp1%)
msg2$ = msg2$ + vert4$(redTmp2%) + vert4$(grnTmp2%) + vert4$(bluTmp2%)
SVGAFont msg2$, 515, 100, 0, 0, 8
PullRGB 11
Example 3
SUB SVGAFont (msg3$, xin, yin, fore, back, size)
msg$ = msg3$
IF msg$ <> "" THEN
CodeCnt = GridCnt(msg$)
IF CodeCnt > 1 THEN
RGBOfs = 0
IF GridMultiVar$(msg$, 0) = "CHAR" THEN
msg2$ = CHR$(GridMulti(msg$, 1))
RGBOfs = 1
ELSE
msg2$ = GridMultiVar$(msg$, 0)
END IF
IF CodeCnt > 1 THEN
z = FNRGBGrab(msg$, 1 + RGBOfs)
PushRGB red%, green%, blue%, 4
z = FNRGBGrab(msg$, 4 + RGBOfs)
PushRGB red%, green%, blue%, 5
END IF
END IF
msg$ = msg2$
L = LEN(msg$)
FOR Lenth = 1 TO L
fontchar = ASC(MID$(msg$, Lenth, 1))
FoxX = fontchar AND 15
FoxY = fontchar \ 16
Explanation
This method of using strings to move multiple values, string elements, and combined values does have disadvantages of course. It relies heavily on slow cumbersome commands to switch back and forth between numeric and string, and is partially recurvsive when used all at once.
Of course this is a modest attempt to move data efficiently, but I think it has at least some place in programs.
One very clear point of doing this is the small footprint that the code makes in the string space. As the values come from a SUB to the main module on returning the results from processing, or sending a multitude of data to a SUB, there is one big thing lacking. Variables.
Instead of using variables to hold the resulting values, you can directly plug in the FUNCTIONS into the target code.
PSET (GridMulti(DataStrg$,0),GridMulti(DataStrg$,1)),GridMulti(DataStrg$,1)
Plainly speaking, the largest volume of dynamic variables are the strings that contain the data chains. Instead of defining global variables to accomidate every SUB or FUNCTION or otherwise, all the data can be packed neatly into a chain that the target routine can then decode and assemble all the information it's working on processing for you.
Of course there are local static variables in every module that must remain, but the global variables are cut back significantly.
DataStrg$ = "COLOR;FF;PRINT;30;30;"
x=MouseX 'x = 20
DataStrg$=GridDelta$(DataStrg$,vert$(x),3))
Now,.. PRINT DataStrg$
? COLOR;FF;PRINT;20;30;
DataStrg$ = "___;___;___;___;___"
' ^______________________ element 0
' ^___________________ element 1
' ^______________ element 2
' etc....
I have modified many of my more complex routines to accept data chains instead of a multitude of variables.
Another plus of using this to send data is the ability to send LESS DATA TO YOUR ROUTINES.
Using some simple logic to parse the data chain, your routine can check for more commands emebeded in the chain to react to and operate on. Of course, you cannot omit variables from a SUB or FUNCTION, unless you are Houdini, but you can create a data chain that is quite short, or really really long, and make your routine work as easy or as hard as you want it to. If you have a very complex routine that functions on many different levels of complexity, you can use this to make your routine accessable to beginners using your routine at first.
The basic premise of this entire slew of command encoding came from rewriting a QBasic ANSI parser to operate as a language to draw graphics, similar to RIP graphics.
One of the drawbacks of using my code is, the marker that separates the data is an ascii character, so if you encode data as raw ascii, you might accidentally put in a marker without trying to. You will have to use MSB / LSB to split your data up into nibble sized pieces and double the length of your data chain, but the end result is in your hands ultimately.
The other originator of this code was a method to hold alot of data in a single file to be able to sort later. I used the traditional buffer size, 64000 and worked from there. I took that amount down a little bit to allow for overflow. 60,000. 60,000 \ 60 = 1000. 1000 entries, each at 60 bytes. I used a start and end marker in the fashion of ANSI,.. "&data;data;data;data;" The end marker was optional cause I would usually run to the end of the 60 character length. Technically, it would only be 59 usable bytes.. Each of these 60 character lengths I called carrots for some odd reason.. cause they are all the same length. 1000 is useful too, because we can make an index of 1 to 1000, or 10 10x10 boxes, or a matrix of 10x10x10. Using different pointer schemes of course is dependent on the application. I would only be able to hold string data along with the same data in the same carrot elements, so that means I would have to figure out a means to link broken strings that went over the 59 character limit. Needless to say, the limit on strings at less that 59 characters made using this file system unappetizing, but it has been used in a few numeric only encoding schemes. There is enough room to keep track of file names using the old DOS 8 character name method .. DOCUME~1 ... (the WinXP lingo method too.. ), and I have run into the little minor difficulty of having a programming directory of over 2000 files. Creating a list of every file to look through and select from within the memory of my programs has become unfeasable. I have been leaning to searching by extension before searching files, or debating creating an indexing routine that would let the program search an external database of the files in the directory to handle high volumes. (I save my files way too much..)
The trick of QBasic, is to utilize memory in a cyclic and recyclable fashion, to make use of every ounce of free space either fine tuned to a few extra lines of code, or move the most data with the least stress on the overall memory usage.
I hope this comes in useful to at least a few people.
Pete's QBZine is the most creative endevor I have seen!
Sincerely,
Paul Holmlund aka Kiyote Wolf
Download a copy of this tutorial: kiyote_wolf_string_stacks.txt
The Art of Rounding
Written by Edward F. Moneo
This tutorial includes coded algorithms in Microsoft QuickBasic 4.5, and therefore the code may not apply to other programming languages.
The term rounding encompasses several methods for converting numbers to a lesser precision.
Rounding methods are also referred to as rounding modes or rounding rules.
Some reasons for performing rounding are:
- Converting numbers with decimals to whole numbers.
- Converting numbers with three or more decimal places to dollars and cents with two decimal places.
- Converting numbers to a workable value, like PI of 3.14159265 to 3.1416.
- Converting numbers to tens, hundreds, thousands, etc. for reports or charts.
Technical Definition of Rounding:
To adjust numbers to fit a format using a rounding mode.
The FORMAT determines how the rounded result appears.
- Numbers with N number of decimal places, where N can be zero.
- Numbers expressed as hundreds, thousands, millions, etc.
The ROUNDING MODE determines whether to round up or down, truncate, how to handle midway digits like .5, and how to handle negative numbers.
The programmer decides on the FORMAT to be used, and performs the required ROUNDING MODE algorithm. Depending on the FORMAT, the programmer may need to scale the number before and after invoking the algorithm.
ROUNDING TERMINOLOGY:
ROUND-TOWARD-ZERO:
[-Infinity] ----(negatives)----> 0 <----(positives)---- [+Infinity]
- Negatives get rounded toward zero, i.e., to a greater negative number.
- Positives get rounded toward zero, i.e., to a lesser positive number.
ROUND-AWAY-FROM-ZERO:
[-Infinity] <----(negatives)---- 0 ----(positives)----> [+Infinity]
- Negatives get rounded away from zero, i.e., to a lesser negative number.
- Positives get rounded away from zero, i.e., to a greater positive number.
ROUND-TOWARDS-POSITIVE-INFINITY:
[-Infinity] ----(negatives)----> 0 ----(positives)----> [+Infinity]
- Both negative and positive numbers are rounded towards positive infinity.
- Expressed with reference to zero:
- Negatives get rounded toward zero, i.e., to a greater negative number.
- Positives get rounded away from zero, i.e., to a greater positive number.
ROUND-TOWARDS-NEGATIVE-INFINITY:
[-Infinity] <----(negatives)---- 0 <----(positives)---- [+Infinity]
- Both negative and positive numbers are rounded towards negative infinity.
- Expressed with reference to zero:
- Negatives get rounded away from zero, i.e., to a lesser negative number.
- Positives get rounded toward zero, i.e., to a lesser positive number.
ROUNDING MODES AND ALGORITHMS:
ROUND-TOWARD-NEAREST:
You will hear Round-Toward-Nearest or Round-To-Nearest referred to as a rounding mode, but it is only a rounding category or generic concept, and not a precise rounding algorithm.
Round-Toward/To-Nearest, as a concept, encompasses several actual rounding algorithms; such as, the symmetric and asymmetric variations of Round-Half-Up, Round-Half-Down, Round-Half-Even, etc.
From a programming point of view, Round-Toward/To-Nearest by itself is worthless.
SYMMETRIC-ARITHMETIC-ROUNDING:
- Aka Round-Half-Up-Symmetric, Half-Adjusting, Conventional Rounding.
- Negative numbers, whose decimal value is greater than or equal to .5, increase towards negative infinity. Others are truncated.
- Positive numbers, whose decimal value is greater than or equal to .5, increase towards positive infinity. Others are truncated.
- This is the classic or conventional rounding mode which many of us learned in school.
- A rounding factor of .5 is added to the number to be rounded, and the fractional part of the result is truncated.
- In the case of a negative number, the same operation is performed on the absolute value of the number.
Algorithm code:
RoundedResult = SGN(Number)*INT(ABS(Number)+.5)
An alternate method:
RoundedResult = FIX(Number+.5*SGN(Number))
Examples:
Negative Values: -2.7 -2.5 -2.3 -2.0 -1.7 -1.5 -1.3 -1.0 -0.7 -0.5 -0.3
Rounded Results: -3 -3 -2 -2 -2 -2 -1 -1 -1 -1 0
Positive Values: +0.0 +0.3 +0.5 +0.7 +1.0 +1.3 +1.5 +1.7 +2.0 +2.3 +2.5 +2.7
Rounded Results: 0 0 +1 +1 +1 +1 +2 +2 +2 +2 +3 +3
ASYMMETRIC-ARITHMETIC-ROUNDING:
- Aka Round-Half-Up-Asymmetric.
- Both negative and positive numbers increase towards positive infinity when the decimal value is greater than or equal to .5.
- Others are truncated.
Algorithm code:
RoundedResult = INT(Number+.5)
Examples:
Negative Values: -2.7 -2.5 -2.3 -2.0 -1.7 -1.5 -1.3 -1.0 -0.7 -0.5 -0.3
Rounded Results: -3 -2 -2 -2 -2 -1 -1 -1 -1 0 0
Positive Values: +0.0 +0.3 +0.5 +0.7 +1.0 +1.3 +1.5 +1.7 +2.0 +2.3 +2.5 +2.7
Rounded Results: 0 0 +1 +1 +1 +1 +2 +2 +2 +2 +3 +3
BANKERS' ROUNDING:
- Aka Round-Half-Even, RoundTiesToEven, Unbiased Rounding, Convergent Rounding, Statistician's Rounding, Round to Nearest Even, Round to Even.
- Symmetrical by definition.
- Some people learned this mode in school. Similar to Symmetric-Arithmetic, with the exception that halfway values of .5 are rounded towards the nearest even digit. The theory is that this more or less evenly distributes upward and downward rounds of exact halves, which might reduce the overall error in a computation that involves many roundings.
Algorithm code:
RoundedResult = CINT(Number)
or alternate method using integer divide.
RoundedResult = Number\1
Examples:
Negative Values: -2.7 -2.5 -2.3 -2.0 -1.7 -1.5 -1.3 -1.0 -0.7 -0.5 -0.3
Rounded Results: -3 -2 -2 -2 -2 -2 -1 -1 -1 0 0
Positive Values: +0.0 +0.3 +0.5 +0.7 +1.0 +1.3 +1.5 +1.7 +2.0 +2.3 +2.5 +2.7
Rounded Results: 0 0 0 +1 +1 +1 +2 +2 +2 +2 +2 +3
ROUND-CEILING:
- Rounds towards positive infinity.
Algorithm code:
if Number < 0 then
RoundedResult=FIX(Number)
else
if Number=FIX(Number) then
RoundedResult=Number
else
RoundedResult=INT(Number)+1
end if
end if
Examples:
Negative Values: -2.7 -2.5 -2.3 -2.0 -1.7 -1.5 -1.3 -1.0 -0.7 -0.5 -0.3
Rounded Results: -2 -2 -2 -2 -1 -1 -1 -1 0 0 0
Positive Values: +0.0 +0.3 +0.5 +0.7 +1.0 +1.3 +1.5 +1.7 +2.0 +2.3 +2.5 +2.7
Rounded Results: 0 +1 +1 +1 +1 +2 +2 +2 +2 +3 +3 +3
ROUND-FLOOR:
- Rounds towards negative infinity.
Algorithm code:
RoundedResult=INT(Number)
Examples:
Negative Values: -2.7 -2.5 -2.3 -2.0 -1.7 -1.5 -1.3 -1.0 -0.7 -0.5 -0.3
Rounded Results: -3 -3 -3 -2 -2 -2 -2 -1 -1 -1 -1
Positive Values: +0.0 +0.3 +0.5 +0.7 +1.0 +1.3 +1.5 +1.7 +2.0 +2.3 +2.5 +2.7
Rounded Results: 0 0 0 0 +1 +1 +1 +1 +2 +2 +2 +2
ROUND-TOWARD-ZERO:
- Aka Truncation.
- This is the simplest rounding mode. All digits, usually the decimals, beyond the number required are dropped. The result is a number whose magnitude is always less than or equal to the original value.
- For POSITIVE numbers, perform ROUND-FLOOR.
- For NEGATIVE numbers, perform ROUND-CEILING.
- Or, perform the following algorithm code:
RoundedResult=FIX(Number)
ROUND-AWAY-FROM-ZERO:
- Aka Round toward infinities.
- For POSITIVE numbers, perform ROUND-CEILING.
- For NEGATIVE numbers, perform ROUND-FLOOR.
ROUND-UP:
- When "UP" means heading towards positive infinity, perform ROUND-CEILING.
- When "UP" means an absolute value heading away from zero, perform ROUND-AWAY-FROM-ZERO.
ROUND-DOWN:
- When "DOWN" means heading towards negative infinity, perform ROUND-FLOOR.
- When "DOWN" means an absolute value heading towards zero, perform ROUND-TOWARD-ZERO.
TRUNCATION:
- Aka Chopping.
- Discard any unwanted digits, usually any decimals.
- Perform ROUND-TOWARD-ZERO.
OTHER OBSCURE ROUNDING MODES NOT DISCUSSED HERE.
- Asymmetric Bankers' Rounding
- Round-Half-Down, symmetric or asymmetric
- Round-Half-Odd, symmetric or asymmetric
- Round Half-Integer Away From Zero
- Round-Alternate
- Round-Random
- Round-Toward-Nearest, ties away from zero.
- Round-Toward-Nearest, ties toward zero.
QUICKBASIC CONSIDERATIONS REGARDING ROUNDING:
You cannot assume what rounding mode is used when the QuickBasic manual says that rounding is performed by certain operators and functions. The following are the operators and functions that specify or imply rounding:
- CINT or CLNG: The manual says: "Converts a numeric expression to an integer (or long integer) by rounding the fractional part of the expression." Not stated, but the rounding mode used is Bankers' Rounding.
- INTEGER DIVISION: The manual says: "Before integer division is performed, operands are rounded to integers or long integers..." Not stated, but the rounding mode used is Bankers' Rounding.
Integer Division does a 3 step operation.
1) It rounds the dividend using Bankers' Rounding.
2) It rounds the divisor using Bankers' Rounding.
3) It then divides the dividend by the divisor, and then TRUNCATES the result toward zero. Due to the divide, a "division by zero" error is possible.
- INTEGER ASSIGNMENT: While transforming the floating point expression to an integer, it performs Bankers' Rounding.
- The INT function: The manual says: "Returns the largest integer less than or equal to the expression." The INT actually performs a Round Floor type of Truncation, also referred to as Round Toward Negative Infinity.
- PRINT USING: The manual says: "Numbers are rounded as necessary." Not stated, but the rounding mode used is Symmetric Arithmetic Rounding. Note: when rounding a negative number, like (-.4), Print Using will display a "-0".
Download a copy of this tutorial: rounding.doc
Freebasic Spring Tutorial
Written by Michael "h4tt3n" Nissen
1. INTRODUCTION
Hello everyone and welcome to this FreeBasic tutorial on spring simulation, or more exactly mass-spring-damper simulation. This is still somewhat of a rough draft covering the basics, and I intend to refine it and add some more stuff. Please do post a comment if you feel like it!
Cheers, Michael
2. THE BASICS OF SPRING PHYSICS
This is definitely not intended to be a physics lesson. In other words I'll keep the strictly scientific part at a minimum and focus on how to implement pysics in code rather than do a lengthy and boring lecture on mechanics.
Lets start by looking at how to represent a spring within a computer program. The simplest way to do this is by setting up two endpoint masses in a coordinate system and connect them to each other with a massless spring, like this:

This is a very common way of doing it, and even in very advanced simulations it is most likely done in the same way. You can do this in one, two, or three dimensions depending on your needs, but the physics behind it is still the same.
The spring's job is to keep the two masses at a certain distance from each other at all times by pulling or pushing them. In the following we'll se how this is done from a physical viewpoint. In this tutorial we'll use Newton's three laws of motion when moving objects around:
- Every object in a state of uniform motion (moving or at rest) remains in that state unless an external force is applied to it.
- The relationship between an object's mass m, its acceleration a, and the applied force F is F = m * a.
- For every force (action) there is an equal and opposite force (reaction).
Besides these three laws all you need to know is that
- Acceleration equals change of velocity per time unit: a = dv / dt
and
- Velocity equals change of position per time unit: v = dx / dt
When moving the endpoint masses around in virtual space our "path of calculation" is:
Force --> Acceleration --> Velocity --> Position
In relation to spring physics, this is how it works:
First we calculate the spring force, using the so called Hooke's law of elasticity. This equation approximates the force applied by a spring as a function of its deformation
F = -K * X
where F = Force, K = spring stiffnes constant, and X = the difference between the springs actual length and its neutral length or "rest length". A more reader friendly way of writing it might be:
Force = -stiffnes * (length - rest length)
The spring stiffnes constant is simply an arbitrary positive number which defines the springs hardness. A low value gives a soft, rubbery spring, and a high value results in rigid, steel-like behaviour.
The spring's rest length is usually a predefined constant. The spring force equation (Hooke's law) will try to keep the spring at that length by applying a force on the two endpoint masses, thus accelerating them towards or away from each other. This is how it works:
If the spring's length is identical to its rest length, then the expression
length - rest length = 0
which means no force is applied on the end masses. If the spring is squeezed shorter than its rest length then
length - rest length < 0
which means that F > 0 ie. an "outwards" force is applied to the two endpoint masses, pushing them away from each other. If on the other hand the spring is stretched longer than its rest length, then
length - rest length > 0
which results in a negative force value ie. an "inwards" force, which will try to pull the endpoint masses back towards each other. Here is an illustration:

Once we've calculated the right force, we need to convert it into acceleration. From Newton's 2nd law we know that
Force = mass * acceleration
which means that
acceleration = Force / mass
Please note that if the two endpoints have different masses they will experience different acceleration, even though they are influenced by the same force. So, although we only need to calculate one force, we still need to calculate the acceleration of each mass separately:
acceleration(endpoint 1) = -Force / mass(endpoint 1)
acceleration(endpoint 2) = Force / mass(endpoint 2)
According to Newton's 3rd law each force is accompanied by an equal opposite force, hence the terms "Force" and "-Force" in the equations.
From the acceleration we need to find the change of velocity of the spring endpoint masses. Here we use the fact that acceleration equals change of velocity per time step
a = dv / dt
Which means that
dv = a * dt
Where a = acceleration, dv = delta velocity (change in velocity), and dt = delta time (time step).
Delta time or time step is simply a positive numerical value which decides how fast the simulation runs. Smaller values result in a slower but more accurate simulation, while bigger values means faster simulation speed at the cost of acccuracy.
Please note that we haven't actually calculated velocity, but [i]change in[/i] velocity. The new velocity value is simply found by adding the delta velocity value to the current velocity
v(new) = v(old) + dv
Finally we need to find the new position of the masses based on velocity. Here we need to know that velocity equals change in position per time step
v = dx / dt
which means that
dx = v * dt
Where dx = delta position (or change in position), v = velocity, and dt = delta time.
Again, since we've only found the change in position, the actual new position is found by adding delta position to the current position value
x(new) = x(old) + dx
So, finally we've come all the way from spring deformation through force, acceleration, velocity, and to the resulting new positions of the spring endpoint masses!
And now I think it's time to look at an example program. Here is a simple one dimensional spring simulation which implements what we've gone through in the above. Play around with it until you feel comfortable with the principles that makes it work. Also, try to find the limits of the simulation. For instance, try to find the highest acceptable time step and spring stiffnes values.
' Michael "h4tt3n" Nissen's mass-spring-damper tutorial, October 2007
'
' Example # 1
'
' Simple one dimensional spring simulation. The spring is represented both
' graphically and numerically. Change the constants defining the spring and
' see what happens! (Press esc to quit)
'
'******************************************************************************'
'' set constants. experiment with these and see how the simulation reacts
const Pi = 4*Atn(1) '' Pi (better not change this ^^)
const Mass_1_mass = 100 '' set mass of the spring's endpoints
const mass_2_mass = 20 '' set mass of the spring's endpoints
const spring_distortion = 50 '' how stretched the spring is at startup
const spring_rest_length = 200 '' spring neutral length or rest length
const spring_stiffnes = 50 '' spring stiffnes. Larger equals stiffer
const timestep = 0.01 '' delta time. Smaller is slower but more accurate
'' dimension variables
Dim as Double time_passed, Spring_length, Force, _
Mass_1_Acceleration, Mass_2_Acceleration, _
Mass_1_Velocity, Mass_2_Velocity, _
Mass_1_Position, Mass_2_Position, _
Mass_1_Radius, Mass_2_Radius
'' set startup position of masses
Mass_1_Position = 300-(spring_rest_length+spring_distortion)/2
Mass_2_Position = Mass_1_Position + spring_rest_length + spring_distortion
'' set mass radius using the equation of a sphere's volume
Mass_1_Radius = ((Mass_1_mass/0.01)/((4/3)*pi))^(1/3)
Mass_2_Radius = ((Mass_2_mass/0.01)/((4/3)*pi))^(1/3)
'' set screen to 600 * 400 pixels * 16 bits per pixel
Screenres 600, 400, 16
'' main program loop
Do
'' first we find the length of the spring
spring_length = Mass_2_Position - Mass_1_Position
'' then we calculate the force with Hooke's law of elasticity
Force = -Spring_stiffnes * (spring_length - spring_rest_length)
'' now we can find the acceleration based on Newton's 2nd law, a = F/m
'' Since the two masses may be different we have to calculate their
'' acceleration separately.
'' (According to Newton's 3rd law each force is accompanied by an equal
'' opposite force, hence the terms "Force" and "-Force" in the equations.)
Mass_1_Acceleration = -Force / mass_1_mass
Mass_2_Acceleration = Force / mass_2_mass
'' then we find change in velocity and add it to the existing velocity
mass_1_Velocity += mass_1_Acceleration * timestep
mass_2_Velocity += mass_2_Acceleration * timestep
'' finally we find the change in position and add it to the existing position
Mass_1_Position += mass_1_velocity * timestep
Mass_2_Position += mass_2_velocity * timestep
'' keep track of time (just for fun. We don't need it for any calculations)
time_passed += timestep
'' display the spring in numbers and graphics
Screenlock
'' clear screen
Cls
'' print various info
Color RGB(64, 255, 64)
Locate 2, 2,: Print "green = constant"
Locate 2, 55: Print Using " time step: #.### s"; timestep
Color RGB(255, 255, 255)
Locate 4, 2,: Print "white = variable"
Locate 4, 55: Print Using "time passed: ###.# s"; time_passed
'' print spring data
Color RGB(192, 192, 192)
Locate 8, 26: Print "------ SPRING DATA ------"
Color RGB(64, 255, 64)
Locate 10, 23: Print Using " stiffnes: ######.## N/m"; spring_stiffnes
Locate 12, 23: Print Using " rest length: ######.## m"; Spring_rest_length
Color RGB(255, 255, 255)
Locate 14, 23: Print Using "spring length: ######.## m"; spring_length
'' print mass 1 data
Color RGB(192, 192, 192)
Locate 20, 7: Print "------ MASS 1 DATA ------"
Color RGB(64, 255, 64)
Locate 22, 4: Print Using " mass: ######.## kg"; Mass_1_mass
Color RGB(255, 255, 255)
Locate 24, 4: Print Using " force: ######.## N"; -Force
Locate 26, 4: Print Using " acceleration: ######.## m/s^2"; Mass_1_Acceleration
Locate 28, 4: Print Using " velocity: ######.## m/s"; Mass_1_Velocity
Locate 30, 4: Print Using " ( position: ######.## )"; Mass_1_Position
'' print mass 2 data
Color RGB(192, 192, 192)
Locate 20, 45: Print "------ MASS 2 DATA ------"
Color RGB(64, 255, 64)
Locate 22, 42: Print Using " mass: ######.## kg"; Mass_2_mass
Color RGB(255, 255, 255)
Locate 24, 42: Print Using " force: ######.## N"; Force
Locate 26, 42: Print Using " acceleration: ######.## m/s^2"; Mass_2_Acceleration
Locate 28, 42: Print Using " velocity: ######.## m/s"; Mass_2_Velocity
Locate 30, 42: Print Using " ( position: ######.## )"; Mass_2_Position
'' draw spring
Line(Mass_1_Position, 320)-(Mass_2_Position, 320), RGB(255, 64, 64)
Circle (Mass_1_Position, 320), Mass_1_Radius, RGB(192, 192, 192),,, 1, F
Circle (Mass_2_Position, 320), Mass_2_Radius, RGB(192, 192, 192),,, 1, F
Screenunlock
'' give the computer a break
Sleep 1, 1
Loop Until Multikey(1) '' start all over with the two new position values
End
In the next part of the tutorial we'll go 2D and look further into the mysteries of friction and damping.
Cheers, Michael
This tutorial was originally posted at the Freebasic.net Forums.
File Manipulation In QBasic/FreeBASIC #4: Database Indexing
Written by Stéphane Richard (Mystikshadows)
INTRODUCTION:
Welcome to the 4th part of the series on File Manipulation. It's been a while since I last wrote about this subject. After exchanging a few emails since way back then with a few people about the subject, it seemed that alot of them wated to build on my binary file example. Let's first do a little trip down memory lane and tell you what the first three parts were all about.
- Part 1 - Sequential Files
In this first part I talked about what sequential files were and gave you the code to create a sequential file that held book related information. The code provided read information from the sequential file at the end I gave the code to
create the data file itself.
- Part 2 - Random Access Files
In this second part we covered random access files and what they are good for. We created an example that allowed you to manage a list of contact information that used random access files as it's storage media.
- Part 3 - Binary Files
In this last part of the series we talked about what binary files were exactly, what role they play and how they worked. We created an example that essentially created a storage system that could be defined at runtime and later retrieved.
In this 4th part of the series I will be extending the last example in 3rd part by giving the database structure we created some indexing features so that you can create indexes to present the records in any order you need for the same of your project. We will give our structure the ability to have index references so that al relative indexes can be loaded in one shot and used accordingly.
So let's get started shall we?
WHAT AN INDEX ACTUALLY IS:
An Index is a file that is created and used to present records in a database file in a preset order. That order is typically determined by one of the fields that define a database. It is a technique that saves the trouble of actually sorting every record in a database (which can be quite time consuming in a 2 gigabyte file). Imagine having to load up 35,000 employee records, sorting them all in the order we need and them saving all this back into the database file. Instead you can use index files so that you don't have to worry about loading huge files and sorting them every time you need them in a specific order. The main reasons for using indexes are:
- Smaller files to handle when the time comes to sort them.
- Since records are sorted you can use algorithms to search for a specific records instead of looping through them until you find the right one.
- Increased search speed. Not just because the files are smaller or you can use algorithms to do searches but because index operations are typically done in memory, not on the data file itself except when you need to lead or save the index file.
This last feature we will detail later in this tutorial but for now, what would you say if I told you that in that 35,000 record database, you could find any record located anywhere in the database with 20 comparisons maximum? if you didn't use that you would have to loop through the index records and compare each field in the index with the search criteria which could mean 35,000 IFs in a loop if your record happens to be the last one in the index file. I'll teach you the method later in this document.
WHAT WE NEED TO CREATE INDEX FILES:
In a typical index file there are only two fields to worry about, the record number or file position and the field value that will be used for comparison later in the search operations. So in our example database file we created in the 3rd part of the series, if we want the database indexed on the employee's name, the index file would have the record number and the employee's name as actual fields. The question is now what else is needed in order to make this index functionality within our database structure.
- The Name Of The Index File:
Of course this will help us know exactly which file to either look for to open the index file or which filename to use when we generate this index file.
- A Relation To The field Used:
We need to know this so that we know which field to compare when we go about doing the search algorithms later. This will be stored in our database structure and controled outside the index file itself.
- The Sorting Order:
There's two possible values here, Ascending sort which sorts from A to Z and the Descending sort which sorts from Z to A.
- A Flag To Know We Have Indexes To Open:
Ths will be in our DBHeader structure it will be a simply byte field that will have either 0 if there are no index files or the total number of index files that are to be opened.
The main thing to remember here is that index files are best stured outside the main data file because it gives the main data file more room for extra records this way. Now, with all this information at hand we will be able to modify the code in the 3rd part to allow it to hold and manage index files pretty easily.
IMPLEMENTING THE INDEX FILES:
It's now time to change our structures so that index files can be integrated to it. You can find the code to this right here. We will need to create a user define type to hold the index definitions within the header of our file. Since we are referencing fields we will add these index references after our field definition sections. So then, first we change our HeaderInformation User Defined Type to the following:
' --------------------------------------
' The header to the database structure
' --------------------------------------
TYPE HeaderInformation
DatabaseName AS STRING * 30
DatabaseVersion AS LONG
Created AS STRING * 10 ' STRING representing a date
Modified AS STRING * 10 ' STRING representing a date
FieldCount AS INTEGER
IndexCount AS INTEGER ' Added to manage the number of index files
RecordCount AS LONG
HeaderLength AS INTEGER ' Length of this header structure
RecordLength AS LONG ' Length of the Values taken by a record
RecordOffset AS LONG ' Position of the start of the 1st Record
END TYPE
Next I create a structure that will hold the information described above. The header of the database will include one of these for each index file we define. The structure is as follows:
' -------------------------------------------------------------
' This structure holds information about each index reference
' -------------------------------------------------------------
TYPE IndexInformation
IndexNumber AS LONG
IndexName AS STRING * 50
FieldReference AS INTEGER ' Index reference in Fields() array
SortOrder AS INTEGER ' 0 Ascending, 1 Descending
END TYPE
Finally I also created to user defined types that will hold the contents of the index files. We will be creating one index that will present the records in the employee name ordered alphabetically from A to Z and an index will be by hourly rate and will be in descending order (so that the bigger salary appear first in the list). The user defined types are as follows:
' ---------------------------------------------------------------
' This structure holds information about each name index record
' ---------------------------------------------------------------
TYPE NameIndexInformation
RecordNumber AS LONG
NameValue AS STRING * 40
END TYPE
' ---------------------------------------------------------------
' This structure holds information about each rate index record
' ---------------------------------------------------------------
TYPE RateIndexInformation
RecordNumber AS LONG
HourlyRate AS DOUBLE
END TYPE
With all this in place we create some arrays and variables to work with these user defined types. Below you'll see just what I added, for the original code you can refer to the included source file in the third part of the series above. Here are the variable declarations we'll need.
' ---------------------------
' Globally Shared Variables
' ---------------------------
DIM SHARED DBIndexes(1 TO 2) AS IndexInformation ' 2 Index File References
DIM SHARED WorkLength AS INTEGER
DIM SHARED TotalLengths AS INTEGER
DIM SHARED IndexCounter AS LONG
DIM SHARED InnerLoop AS LONG ' Used for Index Sorting
DIM SHARED OuterLoop AS LONG ' Used for Index Sorting
DIM SHARED WorkIndex AS STRING
'$DYNAMIC
DIM SHARED NameIndex(1) AS NameIndexInformation ' Employee Name Index
DIM SHARED RateIndex(1) AS RateIndexInformation ' Hourly Rate Index
Now,, just like we created an AddField() subroutine to save lines when defining fields for are DBFields() array we will also create a subroutine to add index to our DBIndexes() array. In our example we'll create two indexes but keep in mind you don't always have a fixed number of indexes to deal with, so using an array can become essential in these situations where you don't know how many items you're dealing with. Here's the subroutine to add index definitions.
SUB AddIndex (index AS INTEGER, FileName AS STRING, FieldReference AS INTEGER, SortOrder AS INTEGER)
DBIndexes(index).IndexNumber = index
DBIndexes(index).IndexName = FileName
DBIndexes(index).FieldReference = FieldReference
DBIndexes(index).SortOrder = SortOrder
END SUB
We will use the subroutine above to add our two index definitions to the DBIndexes() array. If you remember the two index files with be one to order the records in alphabetical order by employee name, the second index will be by hourly rate in reverse order (biggest to smallest salary). The code to do that is as defined below:
CALL AddIndex(1, "EMPNAME", 2, 0)
CALL AddIndex(2, "EMPRATE", 10, 1)
After populating the DBHeader user defined type as well as the DBFields and DBIndexes arrays as shown above we can define our recordOffset field and save our complete definition as the header of the database (field definition and index file definitions included). Here is the code that does precisely that:
' -----------------------------------------
' This decides where the record offset is
' based on if index files exist or not
' -----------------------------------------
IF DBHeader.IndexCount = 0 THEN
DBHeader.RecordOffset = WorkLength + TotalLengths
ELSE
DBHeader.RecordOffset = WorkLength + TotalLengths + (DBHeader.IndexCount * LEN(DBIndexes(1))) + 177
END IF
' ----------------------------------------------------------------
' Write The contents of the file definition to the database file
' ----------------------------------------------------------------
DatabaseHandle = FREEFILE
OPEN RTRIM$(DBHeader.DatabaseName) + ".df" FOR BINARY AS #DatabaseHandle
PUT #DatabaseHandle, , DBHeader
FOR Counter = 1 TO UBOUND(DBFields)
PUT #DatabaseHandle, , DBFields(Counter)
NEXT Counter
FOR Counter = 1 TO UBOUND(DBIndexes)
PUT #DatabaseHandle, , DBIndexes(Counter)
NEXT Counter
At this point our database definition is saved to the data file and our record ofset is calculated accordingly. In our example we'll add 4 records to the database just so we can see a good difference later when we display them. To do so, we'll basically populate our CurrentEmployee structure with values and save it to the data file. Here is the code to do that.
' ----------------------------------------------------------------------
' Assign values to the First Employee to be Saved to the database file
' ----------------------------------------------------------------------
CurrentEmployee.EmployeeNumber = 1
CurrentEmployee.EmployeeName = "Stephane Richard"
CurrentEmployee.Address1 = "I don't know"
CurrentEmployee.Address2 = "And I never will"
CurrentEmployee.City = "Somewhere"
CurrentEmployee.State = "Out There"
CurrentEmployee.ZipCode = 12345
CurrentEmployee.Telephone = "(000) 000-0000"
CurrentEmployee.Fax = "(000) 000-0000"
CurrentEmployee.HourlyRate = 37.5
' ---------------------------------------------
' Write this information to the database file
' ---------------------------------------------
PUT #DatabaseHandle, , CurrentEmployee
' ----------------------------------------------------------------------
' Assign values to the Second Employee to be Saved to the database file
' ----------------------------------------------------------------------
CurrentEmployee.EmployeeNumber = 2
CurrentEmployee.EmployeeName = "Kristian Virtanen"
CurrentEmployee.Address1 = "Ain't got a clue"
CurrentEmployee.Address2 = "blueberry hill"
CurrentEmployee.City = "South of North"
CurrentEmployee.State = "down here"
CurrentEmployee.ZipCode = 12121
CurrentEmployee.Telephone = "(111) 111-1111"
CurrentEmployee.Fax = "(111) 111-1111"
CurrentEmployee.HourlyRate = 38.5 ' more than fair on salaries.
' ---------------------------------------------
' Write this information to the database file
' ---------------------------------------------
PUT #DatabaseHandle, , CurrentEmployee
' ----------------------------------------------------------------------
' Assign values to the Second Employee to be Saved to the database file
' ----------------------------------------------------------------------
CurrentEmployee.EmployeeNumber = 3
CurrentEmployee.EmployeeName = "Michael Wirth"
CurrentEmployee.Address1 = "Am not saying"
CurrentEmployee.Address2 = "Highway To Hell"
CurrentEmployee.City = "Not Paradise"
CurrentEmployee.State = "down here"
CurrentEmployee.ZipCode = 131313
CurrentEmployee.Telephone = "(333) 333-3333"
CurrentEmployee.Fax = "(333) 333-3334"
CurrentEmployee.HourlyRate = 48.2 ' more than fair on salaries.
' ---------------------------------------------
' Write this information to the database file
' ---------------------------------------------
PUT #DatabaseHandle, , CurrentEmployee
' ----------------------------------------------------------------------
' Assign values to the Second Employee to be Saved to the database file
' ----------------------------------------------------------------------
CurrentEmployee.EmployeeNumber = 4
CurrentEmployee.EmployeeName = "Dave Osborne"
CurrentEmployee.Address1 = "You wish"
CurrentEmployee.Address2 = "But I don't"
CurrentEmployee.City = "Definitaly Here"
CurrentEmployee.State = "down here"
CurrentEmployee.ZipCode = 141414
CurrentEmployee.Telephone = "(444) 444-4444"
CurrentEmployee.Fax = "(444) 444-4445"
CurrentEmployee.HourlyRate = 58.6 ' more than fair on salaries.
' ---------------------------------------------
' Write this information to the database file
' ---------------------------------------------
PUT #DatabaseHandle, , CurrentEmployee
We now have our data file with the records we want to work with. The next step is to populate our index arrrays and save them to their respective index file.
To do that we'll loop through the records of the database and add items to our index arrays to begin with. Here is the code to do that:
' --------------------------------------------------------------------
' Position our file pointer and loop to read and add values to index
' --------------------------------------------------------------------
CLS
IndexCounter = 0
REDIM NameIndex(1 TO 4) AS NameIndexInformation
REDIM RateIndex(1 TO 4) AS RateIndexInformation
SEEK #DatabaseHandle, DBHeader.RecordOffset
FOR Counter = 1 TO DBHeader.RecordCount
GET #DatabaseHandle, , CurrentEmployee
IndexCounter = IndexCounter + 1
' ---------------------------------------
' Redimension Name Index and Add Values
' ---------------------------------------
NameIndex(IndexCounter).RecordNumber = DBHeader.RecordOffset + ((Counter - 1) * LEN(CurrentEmployee))
NameIndex(IndexCounter).NameValue = CurrentEmployee.EmployeeName
' ---------------------------------------
' Redimension Rate Index and Add Values
' ---------------------------------------
RateIndex(IndexCounter).RecordNumber = DBHeader.RecordOffset + ((Counter - 1) * LEN(CurrentEmployee))
RateIndex(IndexCounter).HourlyRate = CurrentEmployee.HourlyRate
NEXT Counter
This loop populated both our index arrays with elements, you can see that since we're using binary files the record positions are calculated as the offset of the first record plus the record number times the length of a record. Right now the arrays have elements but they are not sorted in the order they need to be. The code that follows sorts both arrays so that records will be in the intended order we'll need.
' -------------------------------
' Sort Name Index Based On Name
' -------------------------------
FOR OuterLoop = 1 TO UBOUND(NameIndex)
FOR InnerLoop = OuterLoop + 1 TO UBOUND(NameIndex)
IF NameIndex(OuterLoop).NameValue > NameIndex(InnerLoop).NameValue THEN
SWAP NameIndex(OuterLoop), NameIndex(InnerLoop)
END IF
NEXT InnerLoop
NEXT OuterLoop
' -------------------------------
' Sort Name Index Based On Name
' -------------------------------
FOR OuterLoop = 1 TO UBOUND(RateIndex)
FOR InnerLoop = OuterLoop + 1 TO UBOUND(RateIndex)
IF RateIndex(OuterLoop).HourlyRate < RateIndex(InnerLoop).HourlyRate THEN
SWAP RateIndex(OuterLoop), RateIndex(InnerLoop)
END IF
NEXT InnerLoop
NEXT OuterLoop
The index files are now created and sorted accordingly and held in their respective arrays. Though you could wait until later in the program to save them let's save them now so that they are saved and we don't have to worry about them. But at this point the index arrays are now ready to be used by the program. So let's save them with the following piece of code.
' ------------------------------------
' Create and populate the Name Index
' ------------------------------------
WorkIndex = RTRIM$(DBIndexes(1).IndexName) + ".IDX"
IndexHandle = FREEFILE
OPEN WorkIndex FOR BINARY AS #IndexHandle
FOR Counter = 1 TO UBOUND(NameIndex)
PUT #IndexHandle, , NameIndex(Counter)
NEXT Counter
CLOSE #IndexHandle
' ------------------------------------
' Create and populate the Rate Index
' ------------------------------------
WorkIndex = RTRIM$(DBIndexes(2).IndexName) + ".IDX"
IndexHandle = FREEFILE
OPEN WorkIndex FOR BINARY AS #IndexHandle
FOR Counter = 1 TO UBOUND(NameIndex)
PUT #IndexHandle, , RateIndex(Counter)
NEXT Counter
CLOSE #IndexHandle
Let's now program the display routines. We will first display the records in the order they were saved in the data file. Then, we will display them in alphabetical name order from A to Z and finally we'll display them in hourly rate so you can see that the index arrays are as they are supposed to be. Here's the code to display the records in all three mentioned orders.
' ---------------------------------------------------------------------------
' Display the records in 1 natural order, 2 name order, 3 hourly rate order
' ---------------------------------------------------------------------------
PRINT "NATURAL ORDER IN THE DATABASE:"
PRINT "------------------------------"
SEEK #DatabaseHandle, DBHeader.RecordOffset
FOR Counter = 1 TO DBHeader.RecordCount
GET #DatabaseHandle, , CurrentEmployee
PRINT LTRIM$(STR$(CurrentEmployee.EmployeeNumber)); " - ";
PRINT CurrentEmployee.EmployeeName;
PRINT USING "##.##"; CurrentEmployee.HourlyRate
NEXT Counter
PRINT
' ---------------------------------------------------------------------------
' Display the records in 1 natural order, 2 name order, 3 hourly rate order
' ---------------------------------------------------------------------------
PRINT "RECORDS SORTED BY NAME:"
PRINT "-----------------------"
FOR Counter = 1 TO UBOUND(NameIndex)
SEEK #DatabaseHandle, NameIndex(Counter).RecordNumber
GET #DatabaseHandle, , CurrentEmployee
PRINT LTRIM$(STR$(CurrentEmployee.EmployeeNumber)); " - ";
PRINT CurrentEmployee.EmployeeName;
PRINT USING "##.##"; CurrentEmployee.HourlyRate
NEXT Counter
PRINT
' ---------------------------------------------------------------------------
' Display the records in 1 natural order, 2 name order, 3 hourly rate order
' ---------------------------------------------------------------------------
PRINT "RECORDS SORTED BY HOURLY RATE (Bigger to smaller rate):"
PRINT "-------------------------------------------------------"
FOR Counter = 1 TO UBOUND(RateIndex)
SEEK #DatabaseHandle, RateIndex(Counter).RecordNumber
GET #DatabaseHandle, , CurrentEmployee
PRINT LTRIM$(STR$(CurrentEmployee.EmployeeNumber)); " - ";
PRINT CurrentEmployee.EmployeeName;
PRINT USING "##.##"; CurrentEmployee.HourlyRate
NEXT Counter
There you have it, the way it works is that in the case of the indexed views (the last 2 loops), instead of looping through the database file, we loop through the index arrays and position the pointer in the data file to the right position as it is stored in the index array (the RecordNumber field of the user defined type). When the pointer is positioned we simply load the record and display it and repeat this for each element of the array. Below is a sample output of what you should see when you run the program.
NATURAL ORDER IN THE DATABASE:
------------------------------
1 - Stephane Richard 37.50
2 - Kristian Virtaken 38.50
3 - Michael Wirth 48.20
4 - Dave Osborne 58.60
RECORDS SORTED BY NAME:
-----------------------
4 - Dave Osborne 58.60
2 - Kristian Virtaken 38.50
3 - Michael Wirth 48.20
1 - Stephane Richard 37.50
RECORDS SORTED BY HOURLY RATE (Bigger to smaller rate):
-------------------------------------------------------
4 - Dave Osborne 58.60
3 - Michael Wirth 48.20
2 - Kristian Virtanen 38.50
1 - Stephane Richard 37.50
As you can see the indexed record are exactly in the expected order. There is one more thing to cover in this tutorial. How to search for a specific record in the data file. OF course the first and oldest method of finding a record is to browse through the index and compare the values. something like the following accomplishes this quite easily.
FOR Counter = 1 TO UBOUND(NameIndex)
IF UCASE$(TRIM$(SearchValue)) = UCASE$(RTRIM$(NameIndex(Counter).NameValue)) THEN
SEEK #DatabaseHandle, NameIndex(Counter).RecordNumber
GET #DatabaseHandle, , CurrentEmployee
PRINT LTRIM$(STR$(CurrentEmployee.EmployeeNumber)); " - ";
PRINT CurrentEmployee.EmployeeName;
PRINT USING "##.##"; CurrentEmployee.HourlyRate
EXIT FOR
END IF
Next Counter
This will loop until it finds the record represented by the SearchValue string variable. If it find it it will display it on the screen, if not, nothing gets displayed. This is great for rather small data files or if you need to perform a specific operation to each record of the data file. But what if you had a huge data file (maybe 500,000 records of information). A loop like the one above can become long and cumbersome to execute just to find a single record. There is a better way and yes, we are about to cover how it works. Let me described to you a search algorithm called the dichotomic search.
THE SEARCH ALGORITHM EXPLAINED:
A Dichotomic Search is actually quite simple in concept. It's only prerequesite is that the array of indexed values being used are sorted alphabetically or numerically (when dealing with numerical values). The general idea of a dichotomic search is what's called a divide and conquer algorithm. Imagine you have a list of 30 alphabetically sorted employee name and you want to find one of these names in particular.
In order to achieve this you will need to keep track of three things. The lower bound of the list (typically the first element in the array at the beginning of the search), the upper bound of the list (the last element of the array at the beginning of the search) and of course which element you are currently comparing. Hence we will need three variables like so:
' ----------------
' Work Variables
' ----------------
DIM LowerBound AS LONG
DIM UpperBound AS LONG
DIM Current AS LONG
Now, assuming the list of names is in an array, we start these variables with these startup values:
' ------------------------
' Startup Initialisation
' ------------------------
LowerBound = LBOUND(NameIndex)
UpperBound = UBOUND(NameIndex)
IF INT(UpperBound - (LowerBOund - 1) / 2) = UpperBound - (LowerBOund - 1) / 2 THEN
Current = INT(UpperBound - (LowerBOund - 1) / 2)
ELSE
Current = INT(UpperBound - ((LowerBOund - 1) / 2) + .5)
END IF
What we did here is assign the upper and lower limits to the upper and lower bounds of the array. The aim of this search is to start at the middle of the list and start comparing. The IF statement I added here will make it so that if we have an uneven number of elements (say we have 31 names instead of 30) the current variables will get the value 16 which is the element in the exact middle of the list when you have an uneven number of elements in the array.
At this point we are ready to begin our search loop. We start by testing the current element to be sure we do need to go into the loop or not. Then once in the loop we cut the list by halves on every itteration by changing either the lower bound (if the search value is greater than the current field) or the upper bound (if the search value is smaller than the current element) and positioning our Current variable to the middle of the new range of elements. Take a look at the code below and I'll explain it after.
' --------------------------------------------------
' If we happen to be on the right record already
' there's no need to go in the loop so we skip it.
' --------------------------------------------------
IF NameIndex(Current).NameValue = SearchValue THEN
DichotomicSearch = NameIndex(Current).RecordNumber
ELSE
DO WHILE UpperBound <> LowerBound OR NameIndex(Current).NameValue <> SearchValue
' --------------------------------------------------
' This will either cut the list upward or downward
' Depending on if the current record is greater or
' lower than the search value being compared.
' --------------------------------------------------
IF NameIndex(Current).NameValue < SearchValue THEN
UpperBound = Current - 1
ELSE
LowerBound = Current + 1
END IF
' -----------------------------------------------
' Once we know which way we need to cut down we
' we reposition Current to the middle of the
' new valid range to look in and compare with
' -----------------------------------------------
IF INT(UpperBound / 2) = UpperBound / 2 THEN
Current = INT(UpperBound / 2)
ELSE
Current = UpperBound / 2 + .5
END IF
' -----------------------------------------------------
' If the current Element is equal to the search value
' we simply exit the loop as we are done comparing
' -----------------------------------------------------
IF NameIndex(Current).NameValue = SearchValue THEN
EXIT DO
END IF
LOOP
' -----------------------------------------------------------
' Since Current could be anywhere when the loop is exited
' we set it to 0 if the current record is not the right one
' which means the record was not found.
' -----------------------------------------------------------
IF NameIndex(Current).NameValue <> SearchValue THEN
Current = 0
END IF
END IF
In order to explain what exactly is happening in this code, I will give you a sample run so that you see how everything works together. We will use our list of 31 elements as an example. Let's assume the record we are looking for is in position 30 in the list.
|
Description
|
Lower Bound
|
Upper Bound
|
Current
|
Range
|
1. Initial State
2. First Cut
3. Second Cut
4. Third Cut
5. Fourth Cut
|
1
17
24
28
30
|
31
31
31
31
31
|
16
16
16
16
16
|
31
15
8
4
2
|
As you can see from this table we found our record in 5 comparisons (including the original position we started in). In the traditional approach we would have had to loop 30 times in the data file to compare each record in the data file until we find a match. In a 31 record data file we saved 26 comparisons. Imagine if we had a 5000 or 500,000 record database, imagine all the comparisons we would save in a data file that size. I won't let you figure it out, any records in a 500,000 thousand records could be found in 19 comparisons or less. You would save 499,981 comparisons if you happen to be looking for the last record in the database. Imagine the speed gains from a system like this.
IMPORTANT NOTES ABOUT USING THESE TECHNIQUES:
There are a few things to consider when reading this tutorial and/or attempting to use the included sample source file. These are recommendation in order to help you make the most out of this code and make adapting the code to your project's needs that much easier.
- Database Records and all index files must be in sync:
This means that when you add a record to the data file itself you'll need to be sure to add a corresponding record to each of the maintained index files. This can be done on each file write to the data file or in bulk when exiting the data entry module for example. Likewise, if you delete a record from teh data file, you need to delete it's corresponding index file record in all index files.
- There is a rule for when and how you open your files:
This is more of a balancing act rather than a rule. There'something about open and closing files the least amount of time possible. There is also a recomemndation that states to open a file for the shortest time possible. The balance between how often you open a data file versus how long you open them for make up this recommendation. Sometimes it makes sense to open the fil and keep it opened, other times it makes more sense to open the file, do your work on it and close it right back up.
- Use dynamic arrays whenever possible:
In the case of this tutorial we knew alot of factors about the database system we created, not every database situation will give you these upfront like I did here. The code is already mean to use LBOUND and UBOUND wherever possible to adjust if you add more indexes or fields to the definitions but just to be sure use them unless you're 100% sure the current set values will not change in your proejct ever.
- The code here is tested in QuickBasic:
This should mean that it will work fine in QBasic, QuickBasic 4.5, QuickBASIC P.D.S. 7.1, VB-DOS 1.0 and quite possibly FreeBasic (in -lang qb mode). To have this code work in FreeBasic's native mode you will need to remove the CALL in my subroutine calls as well as changing RTRIM$ to TRIM$ and the rest should work as expected.
By following htese recommendations you will create a system that can adapt to just about any database jobs you can throw at it. After all, what good is it to create something like this if it's not going ot be used in atleast 2 if not all your data file related projects? The important thing here, as with any project is to build it for the needs of today AND tomorrow. This is how you build libraries of stuff you need very often and that you can rely on (if tested accordingly of course). This means that in project like this one it's worth taking the time to plan
IN CONCLUSION:
When would you need something like what I explained in this document? The answer might actually be quite surprising. When you mention databases people automatically think business applications, reporting, Oracle, SQL Server and other database engines like MySQL, PostgreSQL and others. Depending on the type of 3D game youre making, having the ability to move around a file of object definitions for example might prove quite useful especially in games that need to update an environment according to other given sets of parameters. There are other game and tool/utilities that can probably benefit from a good database system like this one too. Maybe you can think of some of these projects already. The bottom line is a database system with good indexing and search algorithms have been used thousands of times in places many people never would imagine and might be more useful even to game designers than expected.
Needless to say the subject coverred here is a more complex one by definition. It's quite possible that not everything listed and explained here might have been crystal clear. A few other things could be coded in order to create a really complete usable system as well. But I blieve this will definitaly put you in the right frame of mind. However, if anything is unclear, feel free to email me about it. I will then do my best to make it clear for you so that you know everything you need to know to start your database related project. Until next time, happy coding, reading, and database indexing.
Stéphane Richard
srichard@adaworld.com
Download INDEXING.BAS, or a copy of the full tutorial: filenamipulation4.zip
A beginner's guide to FMOD
Written by Lachie Dazdarian (November, 2007)
Introduction
This tutorial should introduce you with basics of using FMOD in FreeBASIC programs. It's pretty much the summary of FMOD subs and methods I use in my projects and does not represent the entire scope of FMOD in FreeBASIC. If your needs extend beyond this tutorial, you are encouraged to explore additional FMOD calls and its documentation.
Originally I planed to write a cross FMOD/FBSound tutorial, but as FBSound felt rather user-unfriendly to me I gave up on that. If someone likes and prefers FBSound, be so kind to write a tutorial about it in the style of this one if you wish to popularize the library in question.
What is FMOD?
FMOD is a 32-bit sound library for Windows, Linux and Macintosh. It is free of charge for freeware products, but if you plan to use it in commercial products you'll have to buy a specific license. Visit www.fmod.org for more info on this.
What do you need?
Well, you need FreeBASIC first. I assume you have one. As the code in this tutorial was written in FreeBASIC ver.0.18 or later, get that.
You also need FMOD.DLL placed in Windows/System32 directory or where you place the program source code. Get it here: http://www.fmod.org/index.php/download#FMOD3ProgrammersAPI
To test the example program in this tutorial download the following sound files: fmodtutfiles.zip
Initiating FMOD
To use FMOD in your programs you need to include "fmod.bi" with:
#include "fmod.bi"
After this we'll declare several variables that will become necessary later.
CONST number_of_sound_effect = 10
CONST FALSE = 0
CONST TRUE = 1
DIM SHARED PlaySound AS INTEGER
DIM SHARED sample(number_of_sound_effect) AS INTEGER PTR
DIM SHARED music_handle AS INTEGER PTR
DIM SHARED SFXVolume AS INTEGER, MusicVolume AS INTEGER
PlaySound will be used to flag if FMOD functions should be used or not (if FMOD initiation failed), sample array will hold the sound effects and declare it like I did. number_of_sound_effect represent the number of sound effects you'll use in your program. Change this number to suit your own needs. music_handle will flag the current music track in memory which we'll stream. I advise streaming music files instead loading all of them into memory.
SFXVolume will flag the current sound effects volume, while MusicVolume the music volume.
The following code initiates FMOD:
PlaySound = TRUE
FSOUND_Init(44100, number_of_sound_effect+1, 0)
IF FSOUND_Init(44100, number_of_sound_effect+1, 0) = 0 THEN PlaySound = FALSE
PlaySound is set as TRUE by default, and then it's set to FALSE if FMOD fails to initiate. The first parameter in FMOD_Init is mixrate in Hz, usually set to 44100 as most sound files have that mixrate. The second parameter is the number of SOFTWARE channels available. I added one more channel on the number of sound effects I�ll use because I need one more for my music track. You can put any number here, just make sure it's more than the number of sound effects and music tracks you'll allocate at the same time in your program.
Loading samples
To load a sound effect use FSOUND_Sample_Load function on the following way:
IF PlaySound = TRUE THEN
sample(1) = FSOUND_SAMPLE_Load(FSOUND_FREE,"sound1.wav",0,0,0)
sample(2) = FSOUND_SAMPLE_Load(FSOUND_FREE,"sound2.wav",0,0,0)
END IF
The first parameter flags the sample slot (index). FSOUND_FREE chooses an arbitrary one. The second parameter is the name of the sound file. You can load MP3, WAV, OGG, RAW, and other file formats with this function. With the third parameter you can set the mode for that sound effect (check FMOD documentation for the description of available modes), fourth one flags the offset inside the file, and the last one flags the length of a memory block for that sound effect. Unless having special requirements, use zeros for those parameters as I did.
Let's set the default music and sound effects volumes:
SFXVolume = 3
MusicVolume = 3
I use 4 steps volume but you can use more. In my method 4 represents maximum volume, 3 is 75 % of maximum volume, 2 is 50 %, 1 is 25 %, and 0 is mute.
To start streaming a music (or environmental) track I constructed the following subroutine:
SUB playStreamMusic (musc As String)
DIM SetVol AS INTEGER
IF PlaySound = TRUE THEN
music_handle = FSOUND_Stream_Open(musc, FSOUND_LOOP_NORMAL, 0, 0 )
FSOUND_Stream_Play(1, music_handle)
IF MusicVolume = 0 THEN SetVol = 0
IF MusicVolume = 1 THEN SetVol = 63
IF MusicVolume = 2 THEN SetVol = 126
IF MusicVolume = 3 THEN SetVol = 190
IF MusicVolume = 4 THEN SetVol = 255
FSOUND_SetVolumeAbsolute(1, SetVol)
END IF
END SUB
Be sure to declare this subroutine.
To use the subroutine in our specific example input the following line after sample loading:
playStreamMusic ("river.ogg")
FSOUND_Stream_Open opens a sound file for streaming. The first parameter flags the sound file (string), the second parameter flags the mode of streaming (how the file should be played; refer to FMOD documentation for more info on this), and the last two parameters are 0 by default and flag the offset and length of a memory block for the streamed sound file. FSOUND_Stream_Play starts streaming the file flagged with music_handle. I used channel index 1 because we'll use the same to control the volume of the streamed music track (a way to divide the volume of sound effects and music). Note how I used MusicVolume to set the volume of the streamed track (255 max, 0 mute). FSOUND_SetVolumeAbsolute sets a channel volume linearly. This function is NOT affected by master volume. It is used when you want to quiet everything down using FSOUND_SetSFXMasterVolume, but make a channel prominent.
To stop streaming a sound file (which is usually a music track) I use the following subroutine:
SUB stopStreamMusic()
IF PlaySound = TRUE THEN
FSOUND_Stream_Stop music_handle
FSOUND_Stream_Close music_handle
END IF
END SUB
I recommend you to stop streaming a file before you change it to another one. If you are more imaginative, you can come up with volume fade in / fade out effects when tracks are changed, but I don't want to complicate this tutorial with that.
For playing sound effects I use the following subroutine in conjunction with a volume setting subroutine:
SUB playsample (plsnd as integer ptr)
IF PlaySound = TRUE THEN
FSOUND_PlaySound (FSOUND_FREE, plsnd)
setSoundVolume
END IF
END SUB
SUB setSoundVolume
DIM SetVol AS INTEGER
IF PlaySound = TRUE THEN
IF SFXVolume = 0 THEN SetVol = 0
IF SFXVolume = 1 THEN SetVol = 63
IF SFXVolume = 2 THEN SetVol = 126
IF SFXVolume = 3 THEN SetVol = 190
IF SFXVolume = 4 THEN SetVol = 255
FSOUND_SetSFXMasterVolume(SetVol)
IF MusicVolume = 0 THEN SetVol = 0
IF MusicVolume = 1 THEN SetVol = 63
IF MusicVolume = 2 THEN SetVol = 126
IF MusicVolume = 3 THEN SetVol = 190
IF MusicVolume = 4 THEN SetVol = 255
FSOUND_SetVolumeAbsolute(1, SetVol)
END IF
END SUB
Note how the sound effects volume is set every time a sound effect if played, and how in the same time the music volume (channel 1 volume) needs to be RESET.
To play sound effect 1 use:
playsample (sample(1))
You don't have to use a sample array like it did. If you for example create an integer pointer named splash and properly load a sound effect with it, then you'll use:
playsample (splash)
To test all this code create a loop like this one:
SCREENRES 640, 480, 32, 1, GFX_WINDOWED
DO
IF PlaySound = TRUE THEN FSOUND_Update
LOCATE 1,1
PRINT "PUSH ESC TO END PROGRAM"
PRINT "PUSH 1 AND 2 TO TEST SOUND EFFECTS"
PRINT "PUSH F1 AND F2 TO CHANGE THE WATER SOUND VOLUME"
IF MULTIKEY(SC_1) THEN
playsample (sample(1))
SLEEP 1000
END IF
IF MULTIKEY(SC_2) THEN
playsample (sample(2))
SLEEP 1000
END IF
IF MULTIKEY(SC_F1) THEN
MusicVolume = MusicVolume - 1
IF MusicVolume < 0 THEN MusicVolume = 0
setSoundVolume
SLEEP 1000
END IF
IF MULTIKEY(SC_F2) THEN
MusicVolume = MusicVolume + 1
IF MusicVolume > 4 THEN MusicVolume = 4
setSoundVolume
SLEEP 1000
END IF
SLEEP 10
LOOP UNTIL MULTIKEY(SC_ESCAPE)
FSOUND_Close
Use 1 and 2 to test the two sound effects, F1 and F2 to change the music volume. I've been told that using FSound_Update is not necessary, but heck, it doesn't hurt. Note how FSound_Close is used before the program ends. Always be sure to close FMOD when you end your program.
The entire code so far: codever1.txt
Few more statements I want to show you.
To pause currently streamed music track use:
FSOUND_SetPaused (1, 1)
Note that the first parameter is the channel, so this will work only if you are streaming the music track in that channel.
To start streaming it again use:
FSOUND_SetPaused (1, 0)
And this should cover the basics.
Download the final code with all the necessary files: fmod_example_program.zip
Anyway, this is just the surface of FMOD. I warmly recommend you to explore "fmod.bi" and FMOD documentation and expand on these basics.
Happy coding!
A tutorial written by Lachie D. (lachie13@yahoo.com ; The Maker Of Stuff)
Download a copy of this tutorial and all source code files: Beginners_Guide_To_FMOD.zip
Final Word
That's it for another fantastic issue of QB Express! I hope you enjoyed it.
Like I said in the opening letter, I'm going to do everything I can to get QB Express back on its regular once-a-month release schedule. Everyone likes it when issues come frequently and on a regular schedule, me included. QB Express will return to its former glory!
I am going to force myself to make time for QB Express this month...and I hope you will do the same. Write something! If we all do just a little bit, this magazine will just get better and better.
ISSUE #27 DEADLINE: March 1st, 2008.
As always, please email your submissions to qbexpress@gmail.com. We're looking for all kinds of content, but what would be especially nice would be some EDITORIALS, COMICS and GAME REVIEWS -- something that has been lacking for the past few issues. And be sure to send news briefs in as well!
Until next time...END.
-Pete
Copyright © Pete Berg and contributors, 2008. All rights reserverd.
This design is based loosely on St.ndard Bea.er by Altherac.

